ROOT Version 5.26/00 Release Notes
ROOT version 5.26/00 will be released on December 15 2009. In case you are upgrading from an old version, please read the releases notes of version 5.16, 5.18, 5.20, 5.22 and version 5.24 in addition to these notes.
- Bindings - packages related to the interplay with other programming languages (Python, Ruby)
- Cint - the C++ interpreter
- Core - the basic ROOT functionality
- Geometry - building, representing and drawing geometrical objects
- 2D Graphics - ROOT's two dimensional graphics interface
- 3D Graphics - ROOT's three dimensional graphics interface
- Graphical User Interface - from basic GUI elements to ROOT's own, complete dialogs
- Histograming - counting values, spectra, and drawing them
- HTML - the documentation generator
- Input/Ouput - storing and reading data
- Mathemathics - everything one can use to calculate: minimizers, matrixes, FFT, and much more
- Miscellaneous - things that didn't make it into the other groups: table
- Monte Carlo - monte carlo and physics simulation interfaces
- Networking - network-related parts, e.g. protocols and authentication interfaces
- PROOF - parallel ROOT facility
- RooFit - a fitting library
- RooStats - a collection of statistical tools
- SQL - database interfaces
- TMVA - multivariate analysis tools
- Trees - ROOT's unique container class and related utilities
Binaries for all supported platforms are available at:
http://root.cern.ch/drupal/content/production-version-526
For more information, see:
http://root.cern.ch
The following people have contributed to this new version:
Bertrand Bellenot, CERN/SFT,
Brian Bockelman, UNL,
Rene Brun, CERN/SFT,
Philippe Canal, FNAL,
Olivier Couet, CERN/SFT,
Kyle Cranmer, NYU/Atlas, RooStats
Valeri Fine, BNL/STAR,
Lucie Flekova, CERN/SFT summer student,
Fabrizio Furano, CERN/IT,
Gerri Ganis, CERN/SFT,
Andrei Gheata, CERN/Alice,
Mary-Louise Gill, CERN/SFT summer student,
David Gonzalez Maline, CERN/SFT,
Andreas Hoecker, CERN/Atlas, TMVA
Louis Höfler,
Jan Iwaszkiewicz, CERN,
Daniele Kruse, CERN, GDML
Wim Lavrijsen, LBNL, PyRoot
Alfio Lazzaro, Milano/AtlasMinuit
Sergei Linev, GSI,
Anar Manafov, GSI,
Lorenzo Moneta, CERN/SFT,
Axel Naumann, CERN/SFT,
Eddy Offermann, Renaissance,
Katerina Opocenska, Charles Univ. Prague,
Danilo Piparo, Karlsruhe/CMS, RooStats,
Timur Pocheptsov, JINR/Dubna,
Fons Rademakers, CERN/SFT,
Philip Rodrigues, Oxford, Doc,
Paul Russo, FNAL,
Gregory Schott, Karlsruhe/CMS, RooStats,
Tomasz Sosnicki, CERN/SFT summer student,
Joerg Stelzer, DESY/Atlas, TMVA
Matthew Strait, UMN.edu DOC
Alja Tadel, CERN/CMS, Eve
Matevz Tadel, CERN/Alice, Eve
Wouter Verkerke, NIKHEF/Atlas, RooFit,
Matthias Wolf, Karlsruhe/CMS, RooStats
Core
- The following architectures have been obsoleted: linuxkcc, alphakcc, linuxia64sgi, linuxdeb2ppc, solariskcc, sgikcc and linuxpgcc.
- All of ROOT (not just Core) has been checked by a very nice static code analyzer coverity, see: http://www.coverity.com/. Many of the reports have been fixed. We expect that this further increases the stability of ROOT.
- Add support for 'Dump' and 'Browse' of 'emulated' object.
- TBits equality operator nows return true if the 2 operands have different length and all the bits in the longer TBits that are passed the length of the shorter TBits are zero (i.e. the default value of each bits is zero).
- Properly handle scripts with line longer than 1024 characters.
- Repair the handling of ACLiC options on the command line (for example a.C+g).
- In TClass::BuildEmulatedRealData properly handle the case of TNamed member that are not base class.
- On the command line:
- Fix the tab-completion of filenames in the sub-directories.
- Prevent the unadvertent replacement of an arrow with a dot when the left side is actually a pointer
- More user friendly stacktrace in case of a crash, with hints where the problem might be. On Linux and MacOS X these stacktraces are generated by the script $ROOTSYS/etc/gdb-backtrace.sh. Using the Root.StackTraceMessage resource one can customize the message printed by the script. The entire script can be replaced using the Root.StacktraceScript resource.
- Numerous minor bug fixes...
New module editline
The new module editline enhances the prompt, giving type and syntax feedback using e.g. colors. Class names are highlighted blue when typed, indicating that it is known to ROOT. Matching parenthesis pairs are highlighted green when typed, or when the cursor is moved to a bracket. This works for () {} and [] brackets. Any mismatched brackets (those without a matching partner) will be highlighted red when typed or when the cursor is moved to the bracket. Tab completion output is colored magenta to differentiate between tab completion output and user input.
All of the colors are configurable in the .rootrc file. They can be specified as #rgb or #rrggbb or color names: black, red, green, yellow, blue, magenta, cyan or white. They can be followed by an optional bold (alias light) or underlined. Rint.ReverseColor allows to quickly toggle between the default "light on dark" (yes) instead of "dark on light" (no), depending on the terminal background.
An example configuration would be:
Rint.TypeColor: blue Rint.BracketColor: bold green Rint.BadBracketColor: underlined red Rint.TabColor: magenta Rint.PromptColor: black Rint.ReverseColor: no
The enhanced prompt is available on all platforms with [n]curses, including Linux, Solaris and MacOS; the bold and underline options are available also for black and white terminals. You can export (or setenv) TERM=xterm-256color for nicer colors.
With editline comes also an improved terminal input handler. It supports e.g. ^O (Ctrl-o) to replay the history: suppose you have entered
... root [3] i = func() root [4] i += 12 root [5] printf("i is %d\n", i)
You now want to re-run these three lines. As always, you press the up cursor three times to see
root [6] i = func()
and now press ^O (Ctrl-o) to run the line, and prepare the next line:
root [6] i = func()^O root [7] i += 12^O root [8] printf("i is %d\n", i)^O root [9]
allowing you to re-run that part of the history without having to press the up-arrow again and again.
Currently, editline is disabled on Windows.
I/O
Schema Evolution.
- Change TExMap hash, key and values from (U)Long_t to (U)Long64_t. This makes TExMap streamable in a portable way. On 64-bit platforms there is no difference, but on 32-bit platforms all values will now be 64-bit. This fixes a big portability issue with THnSparse which uses TExMap internally where the versions created on a 32-bit platform could not be read on a 64-bit platform and vice versa.
- Avoid reporting I/O error for members of a class that is used only for a transient member; Concrete implementation of TClassGenerator needs to be updated to also avoid the warnings.
- Fix the rule lookup based on checksum
- Extend support of the schema evolution rules to fixed length array.
- Prevent a process abort (due to a call to Fatal) when we are missing the dictionary for (one of) the content of an STL collection when this collection is 'only' use has a transient member.
- Fix the case where the source and target of a rule have the same name.
- Avoid using the 'current' StreamerInfo to read an older streamerInfo that is missing (in case of corrupted files).
Misc.
- New TFile plugin for the Hadoop Distributed File System (protocol hdfs:)
- Unregister stack objects from their TDirectory when the TList tries to delete them.
- When streaming a base class without StreamerNVirtual() use an external streamer if it was set.
- Many improvement to the I/O run-time performance.
- DCache:
- Increase readahead size from 8k to 128k and make it settable via DCACHE_RA_BUFFER env var.
- dCap client does not ignore ?filetpye=raw and other options, so remove it.
- The function TFile::GetRelOffset is now public instead of protected.
- Corrected the reading of the TFile record of large files.
- MakeProject: several updates to improve support for CMS and Atlas data files (add support for auto_ptr, bitset, class name longer than 255 characters, etc.)
Networking
- NET
- TWebFile
- Several pptimizations in TWebFile improving performance especially for TTree::Map() by about 35%. This has been achieved with a better caching strategy for request strings (especially avoiding to recalculate the auth base64 encoding), and with a drastic optimization in reading the response headers.
- Fixes in the counting of the bytes read.
- TWebSystem
- New implementation of TSystem allowing to use TSystem::AccessPathName() and GetPathInfo() to check if a web file exists and to get its size. Directory browsing is not available yet.
- TWebFile
- NETX
- TXNetFile
- Several fixes and optimisations, mainly in the use of the cache
- Fix an offset issue affecting the use of the cache with files in archives
- TXNetSystem
- A few optimizations in the use of retry mechanism, path locality checks, file online checks.
- A few optimizations in the use of retry mechanism, path locality checks, file online checks.
- TXNetFile
- XROOTD
- Import a new version of XROOTD (20091202-0509)
- Fixes in bulk prepare and sync readv operations
- Add support for 'make install' / 'make uninstall' and other improvements in configure.classic
- Several improvements / fixes:
- reduced memory and CPU consumption;
- extreme cp optimizations;
- windows porting
- new cache policies on the client side
- new listing features implemented recently in the 'cns' module.
- optimizations in cmsd and cnsd (performance improvements)
- support for openssl 1.0.0 (required by Fedora 12)
- Support for if/else if/else/fi constructs
- Several portability fixes
- Support 32-bit builds with icc on 64-bit platforms
- Improved detection of libreadline and lib(n)curses
- Increase the flexibility for configuring with an external xrootd
- Add standard switches to disentangle lib and inc dirs
--with-xrootd-incdir=<path_to dir_containing_XrdVersion.hh>
--with-xrootd-libdir=<path_to_dir_containing_xrootd_plugins_and_libs> - When passing a global xrootd dir with --with-xrootd, check both src/XrdVersion.hh and include/xrootd/XrdVersion.hh so that both build and install distributions are supported
- Add standard switches to disentangle lib and inc dirs
- Fix a problem with the xrootd build when running make via 'sudo' (issue #47644)
- Import a new version of XROOTD (20091202-0509)
SQL
Tree
- Changed the MaxTreeSize default from 1.9 GBytes to 100 GBytes.
- Add new special functions in TTreeFormula (and hence TTree::Draw and TTree::Scan) to calculate the minimun and maximum with an entry:
Min$(formula),Max$(formula):
return the minimun/maximum (within one TTree entry) of the value of the elements of the formula given as a parameter.MinIf$(formula,condition),MaxIf$(formula,condition):
return the minimum (maximum) (within one TTree entry) of the value of the elements of the formula given as a parameter if they match the condition. If not element match the condition, the result is zero. To avoid the the result is zero. To avoid the consequent peak a zero, use the pattern:tree->Draw("MinIf$(formula,condition)","condition");which will avoid calculation MinIf$ for the entries that have no match for the condition.
- Add support in TTreeFormula (and hence TTree::Draw and TTree::Scan) for the ternary condition operator ( cond ? if_expr : else_expr ).
- Significantly (by 2 order of magnitude) improved the performance of TTree::Draw calling C++ functions.
- Replace the function TSelectorDraw::MakeIndex and TSelectorDraw::GetNameByIndex with the function TSelectorDraw::SplitNames.
- Add a return value to SetBranchAddress, a return value greater or equal to zero indicate success, a negative
value indicates failure (in both case, the address is still updated). Example:
if (tree->SetBranchAddress(mybranch,&myvar) < 0) { cerr << "Something went wrong\n"; return; }The possible return values are:- kMissingBranch (-5) : Missing branch
- kInternalError (-4) : Internal error (could not find the type corresponding to a data type number.
- kMissingCompiledCollectionProxy (-3) : Missing compiled collection proxy for a compiled collection.
- kMismatch (-2) : Non-Class Pointer type given does not match the type expected by the branch.
- kClassMismatch (-1) : Class Pointer type given does not match the type expected by the branch.
- kMatch (0) : perfect match.
- kMatchConversion (1) : match with (I/O) conversion.
- kMatchConversionCollection (2) : match with (I/O) conversion of the content of a collection.
- kMakeClass (3) : MakeClass mode so we can not check.
- kVoidPtr (4) : void* passed so no check was made.
- kNoCheck (5) : Underlying TBranch not yet available so no check was made.
- Insure that the TTreeCloner (fast merging) is able to also copy 'uninitialized' TStreamerInfo describing abstract classes.
- Repair several use case of splitting collection of pointers (especially when their split level is 1).
- Several run-time performance improvements.
- In TTree::Fill use fZipBytes instead of fTotBytes for deciding when to flush or autosave.
- Properly handle TTree aliases containing array indices.
- Fix the default sorting order of baskets when the TTree is an older in-memory TTree. Enhance the sort order to use the 'entry number' when the seek position are equal. Consequently the default sort order for an older in-memory TTree is now essentially kSortBasketsByEntry rather than kSortBasketsByBranch (old 'correct' sort order) or 'random' (the 'broken' sort order prior to this release).
IMPORTANT enhancement in TTree::Fill:
Slides from a recent seminar describing the main features of ROOT IO and Trees and the recent improvements described below are available at http://root.cern.ch/files/brun_lcgapp09.pptx or http://root.cern.ch/files/brun_lcgapp09.pdf .
The baskets are flushed and the Tree header saved at regular intervals (See AutoFlush and OptimizeBaskets)
When the amount of data written so far (fTotBytes) is greater than fAutoFlush (see SetAutoFlush) all the baskets are flushed to disk. This makes future reading faster as it guarantees that baskets belonging to nearby entries will be on the same disk region.
When the first call to flush the baskets happens, we also take this opportunity to optimize the baskets buffers. We also check if the number of bytes written is greater than fAutoSave (see SetAutoSave). In this case we also write the Tree header. This makes the Tree recoverable up to this point in case the program writing the Tree crashes.
Note that the user can also decide to call FlushBaskets and AutoSave in her event loop on the base of the number of events written instead of the number of bytes written.
New function TTree::OptimizeBaskets
void TTree::OptimizeBaskets(Int_t maxMemory, Float_t minComp, Option_t *option)
This function may be called after having filled some entries in a Tree using the information in the existing branch buffers, it will reassign new branch buffer sizes to optimize time and memory.
The function computes the best values for branch buffer sizes such that the total buffer sizes is less than maxMemory and nearby entries written at the same time. In case the branch compression factor for the data written so far is less than compMin, the compression is disabled. if option ="d" an analysis report is printed.
This function may also be called on an existing Tree to figure out the best values given the information in the Tree header
TFile f("myfile.root");
TTree *T = (TTree*)f.Get("mytreename");
T->Print(); //show the branch buffer sizes before optimization
T->OptimizeBaskets(10000000,1,"d");
T->Print(); //show the branch buffer sizes after optimization
New interface functions to customize the TreeCache
virtual void AddBranchToCache(const char *bname, Bool_t subbranches = kFALSE); virtual void AddBranchToCache(TBranch *branch, Bool_t subbranches = kFALSE); virtual void PrintCacheStats(Option_t* option = "") const; virtual void SetParallelUnzip(Bool_t opt=kTRUE); virtual void SetCacheEntryRange(Long64_t first, Long64_t last); virtual void SetCacheLearnEntries(Int_t n=10); virtual void StopCacheLearningPhase();
New functionality AutoFlush (and changes to AutoSave)
Implement a new member fAutoFlush in TTree with its getter and setter:void TTree::SetAutoFlush(Long64_t autof)
The logic of the AutoFlush mechanism is optimized such that the TreeCache
will read always up to the point where FlushBaskets has been called.
This minimizes the number of cases where one has to seek backward when reading.
This function may be called at the start of a program to change the default value for fAutoFlush.
- CASE 1 : autof > 0
autof is the number of consecutive entries after which TTree::Fill will flush all branch buffers to disk. - CASE 2 : autof < 0
When filling the Tree the branch buffers will be flushed to disk when more than autof bytes have been written to the file. At the first FlushBaskets TTree::Fill will replace fAutoFlush by the current value of fEntries. Calling this function with autof < 0 is interesting when it is hard to estimate the size of one entry. This value is also independent of the Tree. When calling SetAutoFlush with no arguments, the default value is -30000000, ie that the first AutoFlush will be done when 30 MBytes of data are written to the file. - CASE 3 : autof = 0
The AutoFlush mechanism is disabled.
Changed the default value of AutoSave from 10 to 30 MBytes.
New class TTreePerfStats
This new class is an important tool to measure the I/O performance of a Tree. It shows the locations in the file when reading a Tree. In particular it is easy to see the performance of the Tree Cache. The results can be:- drawn in a canvas.
- printed on standard output.
- saved to a file for processing later.
Example of use
{
TFile *f = TFile::Open("RelValMinBias-GEN-SIM-RECO.root");
T = (TTree*)f->Get("Events");
Long64_t nentries = T->GetEntries();
T->SetCacheSize(10000000);
T->AddBranchToCache("*");
TTreePerfStats *ps= new TTreePerfStats("ioperf",T);
for (Int_t i=0;i<nentries;i++) {
T->GetEntry(i);
}
ps->SaveAs("atlas_perf.root");
}
then, in a root interactive session, one can do:
root > TFile f("atlas_perf.root");
root > ioperf->Draw();
root > ioperf->Print();
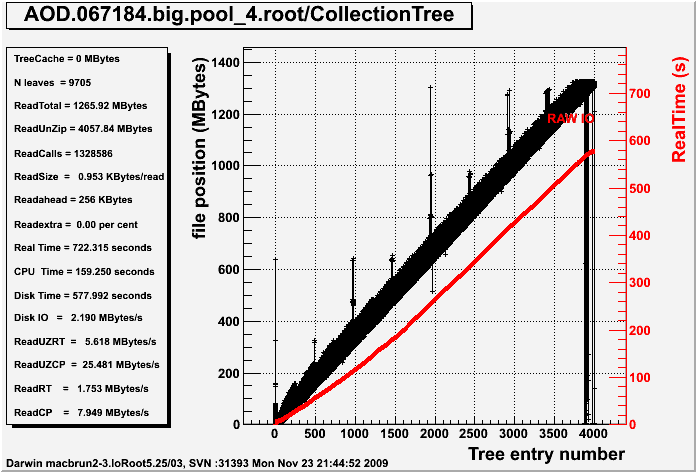
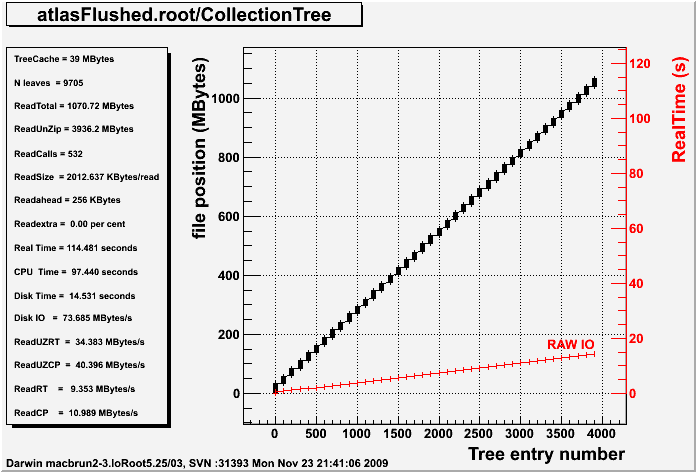
The Draw or Print functions print the following information:
TreeCache = TTree cache size in MBytes N leaves = Number of leaves in the TTree ReadTotal = Total number of zipped bytes read ReadUnZip = Total number of unzipped bytes read ReadCalls = Total number of disk reads ReadSize = Average read size in KBytes Readahead = Readahead size in KBytes Readextra = Readahead overhead in percent Real Time = Real Time in seconds CPU Time = CPU Time in seconds Disk Time = Real Time spent in pure raw disk IO Disk IO = Raw disk IO speed in MBytes/second ReadUZRT = Unzipped MBytes per RT second ReadUZCP = Unipped MBytes per CP second ReadRT = Zipped MBytes per RT second ReadCP = Zipped MBytes per CP second
The Figure below shows the result for an original non optimized file when the Tree Cache is not used.
The Figure below shows the result for the above data file written with the new version of ROOT and when the Tree cache is activated.
Proof
- New functionality
- TProofMgr
- Add support for the following functionality:
- sandbox file listing and browsing
- sandbox file removal
- file upload, download
- See http://root.cern.ch/drupal/content/accessing-sandbox for details.
- Add support for the following functionality:
- TProofDraw
- Allow to set a color, size, size, width for lines, area, markers; the attributes are transmitted via the input list and automatically derived from the ones of the chain
- Support automatic creation of a dataset out of files created on the worker nodes by worker processes. The implementation is an extension of the functionality of the class TProofOutputFile used for merging via file. See http://root.cern.ch/drupal/content/handling-large-outputs-root-files
- Add the possibility to enable/disable the tree cache and
to change its size on per-query base; two new parameters are available:
- PROOF_UseTreeCache Int_t Enable (0) or Disable (1) the tree cache (default 1)
- PROOF_CacheSize Long64_t Cache size in bytes (default 10000000)
a) to disable the cache for the next run enter:
proof->SetParameter("PROOF_UseTreeCache", 0)
b) to set the cache size to 20M
proof->SetParameter("PROOF_CacheSize", 20000000) - Add the parameter
PROOF_UseParallelUnzip to toggle the use of the parallel unzip
(default off for now); to enable it add the following call
proof->SetParameter("PROOF_UseParallelUnzip", 1) - Add the possibility to give indications about
the number of workers at startup.
E.g.
1. To start max 5 workers
TProof::Open("<master>","workers=5")
2. To start max 2 workers per physical machine
TProof::Open("<master>","workers=2x")
This is useful in general when running tests (equivalent but quicker then full startup
followed by TProof::SetParallel(n) or TProof::DeactivateWorker(...)). - Add support for the worker SysInfo_t in TSlaveInfo (obtained via TProof::GetListOfSlaveInfos())
- Add new submerger functionality to speed up the merging
phase. At the end of the query, a set of workers are promoted
submergers and assigned a sub-set of workers to merge. Once each
sub-merger has merged its sub-set of workers, it sends its result to
the master, which merges the partial results into the final
set of results.
The determination of the sub-mergers is always done dynamically, based on the recent performance of workers. An optimal (i.e. giving the highest speed-up) number can be calculated analytically under simple assumptions.
Merging via submergers is by default disabled. To enable it, with the optimal number of sub-mergers, one should set the integer parameter 'PROOF_UseMergers' to 0, i.e.
proof->SetParameter("PROOF_UseMergers", 0)
To force S sub-mergers (regardless of the optimal number) do
proof->SetParameter("PROOF_UseMergers", S)
The new functionality can be tested in tutorials by adding the argument 'submergers' to runProof, e.g.
root [0] .L tutorials/proof/runProof.C+
root [1] runProof("simple(nhist=10000,submergers)")
(see the top of tutorials/proof/runProof.C for additional options).
A test for the submerger functionality has also been added to test/stressProof.cxx . - In PROOF-Lite, add the possibility for the administrator to control the number of workers. This is done using the rootrc variable ProofLite.MaxWorkers, which is read out of /etc/system.rootrc and cannot be overwritten by users. Setting the value to 0 disables PROOF-Lite.
- TProofMgr
- Improvements
- TFileMerger
- A few improvements on the way to make TFileMerger and
hadd totally equivalent:
- import from hadd an optimization of key hashing
- import from hadd a better way to invoke Merge for generic objects
- add option to merge histograms in one go, instead of one-by-one as for generic objects (this option is not yet supported by hadd).
- A few improvements on the way to make TFileMerger and
hadd totally equivalent:
- TProofOutputFile
- Add support for the placeholder <file> the definition of the outputfile. This allows to have complete URL and to pass options to TFile::Open.
- XrdProofd plugin
- Add automatically the line 'Path.ForceRemote 1' to the session rootrc file if the ROOT version is < 5.24/00 ; this acts as a workaround for the wrong TTreeCache initialization at the transition between local and remote files fixed in 5.24/00 .
- Enable mass storage domain settings when working with
TChain's
in multi-master mode. The Mass Storage Domain must be specified as
option in the URL
chain.AddFile("root:// .....?msd=CERN")
and the string must match the value specified in defining the submaster node. - Improved performance monitoring: the 'Rate plot' button
in the dialog box has been renamed 'Performance Plot' and now shows up
to 4 plots as a function of the processing time:
- Instantaneous processing rate, which is now better estimated by a better estimation of the normalizing times
- Average read chunck size, defined as TFile::GetFileBytesRead() / TFile::GetFileReadCalls() during the last unit of time; this allows to monitor the usage of the cache; this plot is present only if some I/O is done, i.e. not for pure CPU tasks.
- The number of active workers
- The number of total and effecive sessions running concurrently on the cluster (started by the same daemon); this plot is present only is the number is at least onec different from 1.
- If enabled, send monitoring information from the master at each GetNextPacket (at each call of TPerfStat::PacketEvent) to allow extrnal real-time progress monitoring.
- Save the status of a 'proofserv' session into a new file
in the 'activesessions' area. The full path of the new file is
<admin_path>/.xproofd.<port>/activesessions/<user>.<group>.<pid>.status
The status indicates whether the session is idle, running or queued.
The status is updated every 'checkfq' secs (see xpd.proofservmgr; default 30 s). The status is dumped by the reader thread of TXProofServ and therefore its r/w access is protected.
- Enable the use of the tree cache also for local files, adapting the default settings for the cache to the recent changes
- In the XrdProofd plug-in
- Improve synchronization between parent and child during fork
- Optimize loops over directory entries
- Improve error and notification messages
- Improved handling of Ctrl-C; this follows from a fix in TMonitor and an improved handling of non-finished query state in the workers (results are not send to master if the query was aborted)
- TFileMerger
- Fixes
- TFileMerger
- Fix a problem preventing correct transmission of all non-mergeable objects (fixes bug #52886)
- Remove the argument isdir from the function MergeRecursive
- Do not remove the first file in the list when returning from MergeRecursive (fixes bug #54591)
- Fix a major leak when merging files with collections written using kSingleKey option. The merger was reading each key in memory and deleted the object at the end, but the container is not owner by default, so all objects inside leaked.
- PROOF-Lite
- Fix a couple of memory leaks showing up when running repeated queries
- Fix a problem in TProofServ::CopyFromCache affecting the case where the sandbox dir has a '.' and the macro name has no '.', e.g. compiled selectors in PROOF-Lite.
- TProofOutputFile
- Fix a problem with the determination of the fDir member affecting mostly PROOF-Lite
- Fix a serious issue whose net effect was to delete the outputfile just after having open it
- XrdProofd plugin
- Make sure that the limit on the number of old sessions is applied whenever a new session is started and not only when the daemon is started.
- Fix the behaviour of the xpd.allowedusers directive: if at least one of these directives is present, users in the password file are not allowed by default but must be explicitly appear in one xpd.allowedusers directive
- Fix a source for memory leak in XrdProofdProtocol::SendMsg
- Optimize the usage of strings in a few places
- DataSet manager
- Correctly classify as TTree all TTree derived classes (e.g. TNtuple's)
- Fix a problem in saving the end-point URL for local files
- Improve realtime notification during 'verify'
- TProofDraw
- Fix a problem with the axis ranges of the underlying histogram in PolyMarker3D
- Allow to use the default pad instead of forcing creation of one pad per object
- Add wrapper to handle the feedback default canvas
- TEventIter
- Fix a problem with changing the tree cache size: the size was reset to the default value after the first file.
- TDataSetManagerFile
- Solve a consistency problem in checking URLs for duplication when adding them to the relevant TFileInfo
- During dataset validation, do not fail on duplications but notify and add them to the bad file list
- TPacketizerAdaptive, TPacketizer
- Improve data node / worker matching by always using the host FQDN
- TPacketizerUnit, TEventIter
- Make sure that the entry number passed to TSelector::Process is unique and in increasing order for non-data driven processing (packetizer TPacketizerUnit). This allows to give a meaning to this variable, for example to related it to one dimension of an integration.
- Fixes in PROOF-Lite:
- Make sure that with envs settings via TProof::AddEnvVar are effective; this enables, for example, the automatic valgrind setup introduced in 5.24/00 or the experiment specific settings via the script defined by the env PROOF_INIT
- Fix a problem with TProof::Load so that now it can be also be used for PROOF-Lite
- TProofPlayerRemote
- In SendSelector, add misisng option kCpBin when sending the selector source; the binary files were never retrieved, even if present and valid
- TProofPlayerSlave
- In Process, fix a problem with cache directory locking while building the selector; the net effect was that each worker process was re-buidling its own selector binary.
- TProofServ
- Fix the order in which the log file is sent in asynchronous processing; the wrong order was screwing up an immediate synchronous query submission after an asynchronous run; this case occured, for example, in 'stressProof' .
- TFileMerger
Histogram package
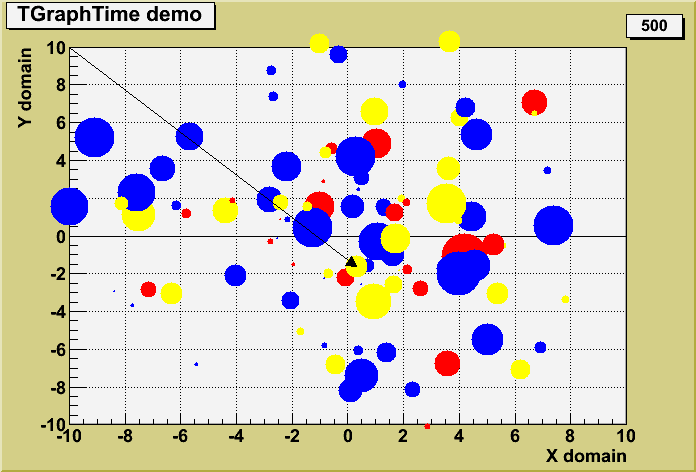
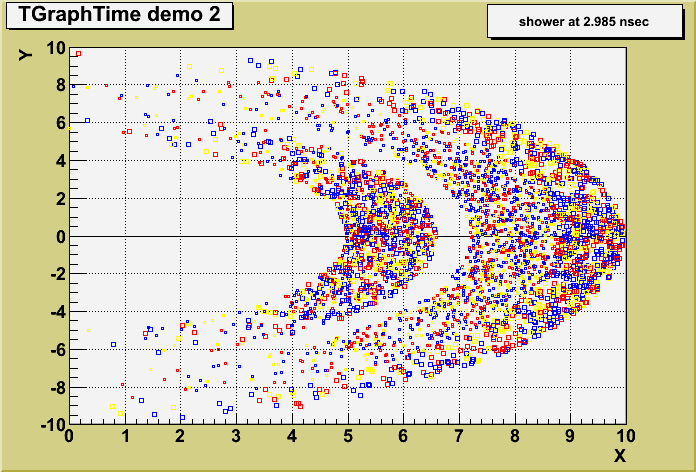
new class TGraphTime
- TGraphTime is a new class to organize and draw a list of objects evolving with time. An example of use is shown in the tutorials $ROOTSYS/tutorials/graphs/gtime.C and $ROOTSYS/tutorials/graphs/gtime2.C.
The tutorial gtime.C shows the evolution of a set of points with time and it produces the following picture.
The tutorial gtime2.C is an example of TGraphTime showing how the class could be used to visualize a set of particles with their time stamp in a MonteCarlo program. It produces the following picture.
THStack
- The following macro produced two sets of superimposed labels with different
text sizes:
{ TH1F *hgaus1 = new TH1F("Hgaus1", "", 100, -10, 10); TH1F *hgaus2 = new TH1F("Hgaus2", "", 100, -20, 20); THStack *hst = new THStack(); hgaus1->FillRandom("gaus", 30000); hst->Add(hgaus1, "ep"); hgaus2->FillRandom("gaus", 30000); hst->Add(hgaus2, "ep"); hst->Draw("nostack"); hst->GetHistogram()->SetLabelSize(0.07, "xy"); } - Change THStack::GetMaximum() and THStack::GetMinimum()
to make sure the error bars fit entirely on the plot when a
THStack is plotted with the option E. The following
macro showed the problem:
{ TH1D *h1 = new TH1D("h1","h1",10,0,10); TH1D *h2 = new TH1D("h2","h2",10,0,10); THStack h; h1->SetLineColor(kRed); h1->SetMarkerStyle(20), h2->SetLineColor(kBlue); h2->SetMarkerStyle(21); for(int i=0; i<11; i++){ h1->SetBinContent(i,1.5-i/10); h1->SetBinError(i,0.5*i); h2->SetBinContent(i,10.5-i/10); h2->SetBinError(i,0.7*i); } h.Add(h1); h.Add(h2); h.Draw("nostack E1"); }
TGraphPainter
- TGraphAsymmErrors and TGraphBentErrors were not correctly clipped when paint with the option E3 (filled band) and zoomed.
- When drawn with the option B, a TGraph had the first or/and last bar missing
if its lowest or/and highest value were equal to the minimum or/and maximum
of the pad. The following lines illustrate the problem:
Int_t x[5] = {0,1,2,3,4}; Int_t y[5] = {10,1,2,3,0}; Int_t n = 5; TGraph *gr = new TGraph(n,x,y); gr->Draw("AB*");This problem was submited here: https://savannah.cern.ch/bugs/index.php?53949
TFormula
- Add support for the ternary condition operator ( cond ? if_expr : else_expr ).
THStack
- The following macro produced two sets of superimposed labels with different
text sizes:
{ TH1F *hgaus1 = new TH1F("Hgaus1", "", 100, -10, 10); TH1F *hgaus2 = new TH1F("Hgaus2", "", 100, -20, 20); THStack *hst = new THStack(); hgaus1->FillRandom("gaus", 30000); hst->Add(hgaus1, "ep"); hgaus2->FillRandom("gaus", 30000); hst->Add(hgaus2, "ep"); hst->Draw("nostack"); hst->GetHistogram()->SetLabelSize(0.07, "xy"); }
TH1
- Fix problem in the resulting statistics of TH1::Add when the coeffient are negative, for an histogram subtraction. This fixes the issue #55911.
- In the implementation of TH1::ResetStats(), set the statistics to the one calculated using the bin center and also reset the number of entries to the total bin content or to the effective entries in case of a weighted histogram.
- Check the histogram compatibility, by comparing each bin, in the case of variable bin histogram, when using the histogram operation methods TH1::Add or TH1::Multiply or TH1::Divide
THistPainter
- Round correctly the number of entries displayed in the statistics box to the closest integer value.
- New plotting option SURF7. It is similar to SURF3 except
that the surface is plotted with colors and the contours on top with lines.
TGraph
- Fixed problem in <http://root.cern.ch/phpBB2/viewtopic.php?t=9208>
TGraphErrors
- Add a new fitting option "EX0", to neglect the error in X when fitting
THnSparse
- Make a function to generate a THnSparse from a corresponding TH1.
- Fixed a problem with the division methods, as well as implement unit tests for them.
- Remove some unnecessary parts of the methods Multiply and Divide.
- Implement the multiplication proposal in <http://root.cern.ch/phpBB2/viewtopic.php?t=7692>, as weel as implemeting unit tests for it.
- Add a new method Fit() for fitting a THNSparse. By default the likelihood method is used. For using a least square method (not really reccomended) if the histogram is really sparse, the option "X" must be used.
new classes TFitResult, TFitResultPtr
- All the Fit methods of the Hist library instead of returning an integer now return a TFitResultPtr object. The TFitResultPtr is an object that converts automatically to an integer, which represents the status code of the fit. If the Fit method is used as before, there is a no visible change for the user.
- When using the fit option "S", the TFitResultPtr will now contain a pointer to the new TFitResult class. It will behave as a smart pointer to TFitResult, by using the -> operator the user can call the TFitResult methods or access directly the TFitResult object, by using the de-reference operator * or TFitResultPtr::Get().
- The TFitResult class derives from the ROOT::Math::FitResult, which contains all the result information from a fit and from TNamed. It provides then I/O capabilities for the FitResult object and convenience methods like Print(), Write(), GetCovarianceMatrix() and GetCorrelationMatrix() which return a TMatrixDSym object.
- Example of usage:
TFitResult r = h->Fit("myFunc","S"); TMatrixDSym cov = r->GetCovarianceMatrix(); // to access the covariance matrix Double_t chi2 = r->Chi2(); // to retrieve the fit chi2 Double_t par0 = r->Value(0); // retrieve the value for the parameter 0 Double_t err0 = r->Error(0); // retrieve the error for the parameter 0 r->Print("V"); // print full information of fit including covariance matrix r->Write(); // store the result in a file
FitPanel
- Added predefined 2D Functions.
- Addition of new minimization algorithms from the GSL library and foreseen the addition of genetic minimizers when will be released.
- Fixed up to three bugs from the previous release
- Added the Update Button. This way the user can update the content of the fitpanel with all the new objects and functions created in the current ROOT session.
- Changed the way the TF1s were being copied internally. Instead of using TObject::Clone, now it's using the TF1 copy constructor
new tutorial rebin.C
This tutorial illustrates how to:- create a variable binwidth histogram with a binning such that the population per bin is about the same.
- rebin a variable binwidth histogram into another one.
CINT
CINT7
After analyzing the results of our integration tests, we came to the conclusion that Cint 7 would not provide any immediate and visible gain in performance or memory use while also not helping us achieve any of the benefits we were aiming for to improve Cint for the LHC experiments; Cint 7 was also not yet to the point of being able to improve on any of the Cint 5 deficiencies or on the lack of support for the upcoming C++ standard. Hence we decided to no longer pursue this direction.
As an alternative we started investigating LLVM, a cutting edge popular open source compiler project that is already used in commercial environments. Apple is currently supporting the main developers and relying on LLVM for Mac OS 10.6 and above. Its strengths include binary platform compatibility, a C++ API, large number of optimizer, and a just-in-time compiler, amongst others; these strengths makes it an ideal candidate for building upon to develop a new interpreter. The LLVM team is currently implementing a promising C/C++ and Objective C/C++ front end (Clang) which can already parse more than 95% of the ROOT header files.
After working with the LLVM and Clang team for a while, we are confident that they will deliver a very good C++ compiler. We believe that we can re-use large parts of it to produce a production-grade interpreter with C++ API, leveraging the large LLVM developer community. Thanks to LLVM, this future interpreter would offer better and faster parsing and execution (for both the dictionary generation and the interpretation). We are currently exploring the implementation of the interpreter and reflection database based on LLVM with an early prototype, code named Cling. Amongst other things, it demonstrate the usability of LLVM's just-in-time compiler.
You can see more details on the Cint7 conclusion as well as LLVM and Cling in Axel's presentation.
Development
All other packages have seen bug fixes and performance improvements. They are all backward compatible with the v5.24/00 release.
- CINT
- Improve the lookup time for type names. Improves start-up time (dictionary initialization) and parsing speed.
- New link pragma to simply the generation of the dictionary for 'operators' in a rootcint dictionary.
#pragma link [C++|off] operators classname;
will turn on/off symbol table registration of the operators that are declared in the declaring scopes of 'classname' (and any of its enclosing scope) and take at least one argument that is a reference, pointer, or value argument of type classname. - Replace most of CINT's static buffers by a custom string class with very fast allocation. This costs <0.5% in runtime, <300kB in heap, and significantly increases CINT's robustness with large type names, source lines etc. It also reduces the stack use of CINT, a problem encountered mostly on Windows.
- CINT now doesn't exit() anymore when encountering fatal errors but throws a runtime_exception.
- Improve handling of nan (not a number).
- Reflex
- Implement loading on demand of data and (most) function members for genreflex dictionaries, similar to what is available for rootcint dictionaries. This reduces the start-up time and especially the memory usage of dictionaries considerably.
- Cintex
- Fix the implementation of ShowMembers in the case where the members are of type with a rootcint dictionary and no genreflex dictionary.
- Don't add artificial Streamer() or StreamerNVirtual() methods to class passed through Cintex anymore. This speeds up the I/O of classes with Reflex dictionaries.
- Only flag the artificial ShowMembers() as virtual if the class already has a virtual function table; otherwise ROOT will wrongly expect the class to have a virtual function table.
PyROOT
Fixes were made to "member-style" access on TTrees, to handle several more common cases, such as where names do not match, and sub-branching. Likewise, TPySelector was improved to handle new use cases where it needed a function default constructor, and where the user wants to change the associated TTree.
It is now possible to use buffers, rather than strings, for char* function arguments.
Math Libraries
TMath
- Add 2 new functions to compare floating points:
Bool_t AreEqualAbs(Double_t af, Double_t bf, Double_t epsilon) { //return kTRUE if absolute difference between af and bf is less than epsilon Bool_t AreEqualRel(Double_t af, Double_t bf, Double_t relPrec) { //return kTRUE if relative difference between af and bf is less than relPrec
TMatrix
Various changes to the Sparse Matrix classes:- Fixed Savannah bugs 45807,45502 and 45415
- added a Streamer function to TMatrixTSparse to remove a memory leak.
- Added vector functionality as proposed by Peter D Barnes from LNL
(http://root.cern.ch/phpBB2/viewtopic.php?t=8351).
double s = v1 * M * v2; // Mult Function : e.g., physics matrix element TMatrixD M = v1' * v2 // outer product of v1 and v2
SMatrix
- Use specialized structures for building automatically static tables for mapping the indices conversion from standard row-wise one to the compact one used internally for storing the memory of a symmetrix matrix. This change gives an improvements of around 10-20% in the Kalman filter test (testKalman.cxx) and in the matrix operations test.
Minuit
- Implement in the TMinuitMinimizer class the method SetPrecision() using the "SET EPS" Minuit command
- Fix a problem when using the user provided gradient in TMinuitMinimizer. The gradient calculation is always forced, i.e. Minuit will always use the derivatives calculations provided by the user. This is now the same behavior as in Minuit2Minimizer.
- Implement in TMinuitMinimizer a method to retrieve the variable name given the index.
- Fix a printout in TMinuit::mnscan and a problem observed with valgrind.
Minuit2
- Fix a bug in MnFunctionCross.
- Add a protection against very small step sizes which can cause nan values in InitialGradientCalculator.
- Implement a new function in the MnUserTransformation class, FindIndex(name), which returns -1 when the parameter name does not exist.
- Implement new methods in Minuit2Minimizer as requested by the Minimizer interface: SetPrecision(double eps) to change the precision value used internally in Minuit2 (in MnPrecision), VariableName(index) to return the name of a variable (parameter) given an index, and VariableIndex(name) to return the index of a variable given a name.
- Set a status code in Minuit2Minimizer according to the following convention:
status = minimizeStatus + 10 * minosStatus + 100 * hesseStatus.
See the Minuit2Minimizer reference documentation for the possible values of minimizeStatus , minosStatus and hesseStatus. - In MnHesse. when the inversion of the hessian matrix failed, return MnInvertFailed instead of MnHesseFailed.
Mathcore Fitting classes
- Fix the fitting with the integral option in multi-dimensions.
- Force the gradient calculation when requested in the minimizer classes and avoid to perform the check when using TMinuit. This was already the case in Minuit2.
- Add new class ROOT::Fit::SparseData for dealing with binned sparse data. This class automatically merges the empty region, so they can be considered, whenever possible as a larger single bin. This improves the performances when doing likelihood fits on the sparse data.
- Fix the likelihood fits for variable bin histograms. Now a correct normalization is applied according to the bin volume.
- Add new methods in Minimizer class :
- Minimizer::SetPrecision(double eps) to change in the minimizer the precision on which the objective functions are evaluated. By default the numerical double precision is used inside the minimizers. This method should be used only if the precision in the function evaluation is worse than the double precision.
- std::string Minimizer::VariableName (unsigned int index) to return a name of the minimizer variable (i.e. a fitting parameter) given the integer index. Return an empty string if the variable is not found or of the minimizer does not re-implement this method.
- int Minimizer::VariableIndex(const std::string & name) to return the index of a variable given a name. Return -1 if the variable is not found or if the specific minimizer does not re-implement this function.
- ROOT::Fit::FitResult: fix a problem in the I/O, the function pointer is now made temporary and cannot be stored. Change also the Print() method to print now the results also when the fit is invalid (when it did not converge correctly).
Unuran
- Add a new version 1.5.0. The new version implements a new method PINV, that is a quite fast numerical inversion method that only requires only the density function of the distribution.
RooFit
New infrastructure for toy MC studies
A new class RooStudyManager has been added that is intended to replace the present RooMCStudy framework for toy MC studies on the time scale of ROOT release 5.26.The present RooMCStudy is a small monolithic driver to execute 'generate-and-fit' style MC studies for a given pdf. It provides some room for customization, through modules inheriting from RooAbsMCStudyModule that can modify the standard behavior, but its design limits the amount of flexibility.
In the new RooStudyManager design, the functionality of RooMCStudy has been split into two classes: class RooStudyManager which manages the logistics of running repetitive studies and class RooGenFitStudy which implements the functionality of the 'generate-and-fit'-style study of RooMCStudy. The new design has two big advantages:
- Complete freedom in the design of studies, either by tailoring the behavior of RooGenFitStudy or by using another study module that inherits from RooAbsStudy, and the data that they return.
- More flexibility in the mode of execution. The new study manager can execute all study modules inlines, as was done in RooMCStudy), but also parallelized through PROOF (at present only PROOF-lite is support, as well as in batch
// Create workspace with p.d.f
RooWorkspace* ww = new RooWorkspace("ww") ;
ww->factory("Gaussian::g(x[-10,10],mean[-10,10],sigma[3,0.1,10])") ;
RooGenFitStudy gfs ;
gfs.setGenConfig("g","x",NumEvents(1000)) ;
gfs.setFitConfig("g","x",PrintLevel(-1)) ;
RooStudyManager mgr(*ww,gfs) ;
mgr.run(1000) ; // execute 1000 toys inline
mgr.runProof(10000,"") ; // execute 10000 toys through PROOF-lite
gfs.summaryData()->Print() ;
Workspace and factory improvements
The workspace class RooWorkspace has been augmented with several new features- The import() method now supports a new argument RenameAllVariablesExcept(const char* suffix, const char keepList) which
will rename all variables of the imported function by extended them with a supplied suffix,
except for a given list of variables, which are not renamed.
- A new utility function importFromFile() has been added, which is similar to import, except that it take a string
specifier for the object to be imported rather than a reference. The string is expected to be of the form
fileName:workspaceName:objectName and simplifies import of objects from other workspaces on file. The importFromFile
accepts all arguments accepted by the standard import() method.
- Generic objects (inheriting from TObject) can now also be stored in the workspace under an alias name, rather
under their own name, which simplifies management of objects of types like TMatrixD that do not have a settable name.
ws.import(matrix,"cov_matrix") ;
- New accessors have been added that return a RooArgSet of all elements of the workspace of a given type, e.g.
allVars(), allPdfs().
-
The Print() method now accepts option "t", which prints the contents tree-style instead of a flat list of components,
as ilustrated below
*** Print() *** p.d.f.s ------- RooProdPdf::bkg[ ptBkgPdf * mllBkgPdf * effBkgPdf|pt ] = 0.267845 RooEfficiency::effBkgPdf[ cat=cut effFunc=effBkg ] = 0.76916 RooEfficiency::effSigPdf[ cat=cut effFunc=effSig ] = 0.899817 RooAddPdf::genmodel[ Nsig * sig + Nbkg * bkg ] = 0.502276 RooPolynomial::mllBkgPdf[ x=mll coefList=(mbkg_slope) ] = 0.775 RooGaussian::mllSigPdf[ x=mll mean=msig_mean sigma=msig_sigma ] = 1 RooExponential::ptBkgPdf[ x=pt c=pbkg_slope ] = 0.449329 RooExponential::ptSigPdf[ x=pt c=psig_slope ] = 0.818731 RooProdPdf::sig[ ptSigPdf * mllSigPdf * effSigPdf|pt ] = 0.736708 functions -------- RooFormulaVar::effBkg[ actualVars=(pt,ab,mb,sb) formula="0.5*@1*(1+TMath::Erf((@0-@2)/@3))" ] = 0.76916 RooFormulaVar::effSig[ actualVars=(pt,as,ms,ss) formula="0.5*@1*(1+TMath::Erf((@0-@2)/@3))" ] = 0.899817 *** Print("t") *** p.d.f.s ------- RooAddPdf::genmodel[ Nsig * sig + Nbkg * bkg ] = 0.502276 RooProdPdf::sig[ ptSigPdf * mllSigPdf * effSigPdf|pt ] = 0.736708 RooExponential::ptSigPdf[ x=pt c=psig_slope ] = 0.818731 RooGaussian::mllSigPdf[ x=mll mean=msig_mean sigma=msig_sigma ] = 1 RooEfficiency::effSigPdf[ cat=cut effFunc=effSig ] = 0.899817 RooFormulaVar::effSig[ actualVars=(pt,as,ms,ss) formula="0.5*@1*(1+TMath::Erf((@0-@2)/@3))" ] = 0.899817 RooProdPdf::bkg[ ptBkgPdf * mllBkgPdf * effBkgPdf|pt ] = 0.267845 RooExponential::ptBkgPdf[ x=pt c=pbkg_slope ] = 0.449329 RooPolynomial::mllBkgPdf[ x=mll coefList=(mbkg_slope) ] = 0.775 RooEfficiency::effBkgPdf[ cat=cut effFunc=effBkg ] = 0.76916 RooFormulaVar::effBkg[ actualVars=(pt,ab,mb,sb) formula="0.5*@1*(1+TMath::Erf((@0-@2)/@3))" ] = 0.76916 - The workspace factory can now access all objects in the generic object store of the workspace, e.g.
TMatrixDSym* cov RooWorkspace w("w") ; w.import(*cov,"cov") ; w.factory("MultiVarGaussian::mvg({x[-10,10],y[-10,10]},{3,5},cov)") ; - The workspace factory now correctly identifies and matches typedef-ed names in factory constructor
specifications.
- All objects created by the factory and inserted by the workspace get a string attribute "factory_tag",
that contains the reduced factory string that was used to create that object, e.g.
RooWorkspace w("w") ; w.factory("Gaussian::g(x[-10,10],m[0],s[3])") ; cout << w.pdf("g")->getStringAttribute("factory_tag") << endl ; RooGaussian::g(x,m,s) - Previously all factory orders that would create objects with names of objects that already existed always
resulted in an error. Now, this will only happen if the factory tag of the existing object is different
from the tag of the existing object
w.factory("Gaussian::g(x[-10,10],m[0],s[3])") ; w.factory("Chebychev::g(x[-10,10],{0,1,2})") ; // Now OK, x has identical spec, existing x will be used.
Improvements to functions and pdfs
- Addition to, reorganization of morphing operator classes.
The existing class RooLinearMorph which implements 'Alex Read' morphing has been renamed RooIntegralMorph. A new class RooMomentMorph has been added (contribution from Max Baak and Stefan Gadatsch) that implements a different morphing algorithm based on shifting the mean and variance of the input pdfs. The new moment morphing class can also interpolate between multiple input templates and works with multi-dimensional input pdfs. One of the appealing features is that no expensive calculations are required to calculate in the interpolated pdfs shapes after the pdf initialization. An extension that allows morphing in two parameters is foreseen for the next root release. - Progress indication in plot projections
The RooAbsReal::plotOn() now accepts a new argument ShowProgress() that will print a dot for every function evaluation performed in the process of creating the plot. This can be useful when plotting very expensive functions such as profile likelihoods - Automatic handling of constraint terms
It is no longer necessary to add a Constrain() argument to fitTo() calls to have internal constraints applied. Any pdf term appearing in a product that does not contain an observable and shares one or more parameters with another pdf term in the same product that does contain an observable is automatically picked up as a constraint term. For example given a dataset D(x) which defines variable x as observable, the default logic works out as followsF(x,a,b)*G(a,a0,a1) --> G is constraint term (a also appears in F(x)) F(x,a,b)*G(y,c,d) --> G is dropped (factorizing term)A Constrain(y) term in the above example will still force term G(y,c,d) to be interpreted as constraint term - Automatic caching of numeric integral calculations
Integrals that require numeric integrations in two of more dimensions are now automatically cached in the expensive object store. The expensive object store allows to cache such values between difference instance of integral objects that represent the same configuration. If integrals are created from an object (function or pdf) that live in a RooWorkspace the expensive object cache of the workspace will be used instead of the global store instance, and values stored in the workspace store will also be persisted if the workspace is persisted. The global caching behavior of integral objects can be controlled through RooRealIntegral::setCacheAllNumeric(Int_t nDimNumMin).
Miscellaneous improvements data classes
- The RooAbsData::tree() method has been restored. It will only return a TTree* pointer for datasets
that are based on a RooTreeDataStore implementation, i.e. not for the composite datasets mentioned below
- A new composite data storage class RooCompositeDataStore has been added that allows to construct composite
RooDataSet objects without copying the input data.
// Make 2 input datasets and an index category RooWorkspace w("w",kTRUE) ; w->factory("Gaussian::g(x[-10,10],m[-10,10],s[3,0.1,10])") w->factory("Uniform::u(x)") w->factory("index[S,B]") RooDataSet* d1 = w::g.generate(w::x,1000) RooDataSet* d2 = w::u.generate(w::x,1000) // Make monolithic composite dataset (copies input data) RooDataSet d12("d12","d12",w::x,Index(w::index),Import("S",*d1),Import("B",*d2)) //----------------------------------------------------------------------------- // NEW: make virtual composite dataset (input data is linked, no data is copied) RooDataSet d12a("d12a","d12a",w::x,Index(w::index),Link("S",*d1),Link("B",*d2)) //----------------------------------------------------------------------------- // Fit composite dataset to dummy model w->factory("SUM::model(fsig[0,1]*g,u)") w::model.fitTo(d12a)
For virtual composite dataset it is also possible to join a mix of binned and unbinned datasets
(representation as a RooDataSet with weights)
- The setWeightVar() method has been deprecated as it is very difficult to support on-the-fly redefinition
of the event weight variable in the new data store scheme. To declare a data set weighed,
use the WeightVar() modifier of the constructor instead,e.g.:
RooDataSet wdata("wdata","wdata",RooArgSet(x,y,wgt),WeightVar(wgt)) ; - The RooHist class that represents data as a histogram in a RooPlot has been modified so that it can show approximate Poisson errors for non-integer data. Thes approximate error are calculated from interpolation of the error bars of the nearest integers. NB: A weighted dataset plotted with RooAbsData::plotOn() will be default show sum-of-weights-squared errors. Only when Poisson error are forced through a DataError(RooAbsData::Poisson) argument these approximate Poisson error bars are shown
Miscellaneous improvements other
- The RooFit messagee service class RooMsgService has been augmented with a stack that
can store its configurate state information. A call to saveState() will save the
present configuration, which can be restored through a subsequent call to restoreState().
- In addition to the method RooAbsArg::printCompactTree() which is mostly intende for debugging, a new method RooAbsArg::printComponentTree() has been added that prints the tree structure of a pdf in a more user-friendly content oriented way. The printing of the leaf nodes (the variables) is omitted in this method to keep the output compact.
RooStats
This release contains significant bug fixes and it is strongly reccomended to update to this version if using older ones.Major Changes in LimitCalculator and HypoTestCalculator classes: usage of ModelConfig class
-
The RooStats calculator interfaces have been changed to use the ModelConfig class.
All the setter methods with the parameter lists, pdf instances and name have been removed from the interfaces.
The SetWorkspace(RooWorkspace & ) has also been removed, while a SetModel(const ModelConfig &)
function is introduced.
-
Users are supposed to pass all the model information using the
ModelConfig class rather than via the
RooWorkspace or specifying directly the pdf and parameter
objects in the constructors.
Setter methods using pdf instances and parameter lists are maintained in the derived classes, like the ProfileLikelihoodCalculator or the HybridCalculator, but those passing a string for the name of the pdf have been removed.
- All the calculator classes do not keep anymore a pointer to the workspace, but they contain pointers to the pdf, the data and the parameters required to run the calculator. These pointers are managed outside by the users or by the RooWorkspace. They can be passed either directly to the classes, for example via the constructor, or by using the ModelConfig class. The ModelConfig class acts as an interface to the Workspace in order to load and store all the needed information.
ProfileLikelihoodCalculator, LikelihoodInterval
- The Minos algorithm of Minuit is used now to find the limit of the likelihood intervals instead of searching directly the roots of the RooProfileLL class. Minos is used via the ROOT::Math::Minimizer interface. By default TMinuit is used, one can also use Minuit2 by doing ROOT::Math::MinimizerOptions::SetDefaultMinimizer("Minuit2").
- The LikelihoodInterval class now provides now two new methods, FindLimits which finds both the upper and lower interval bounds, and GetContourPoints to find the 2D contour points defining the likelihood interval. GetContourPoints is now used by the LikelihoodIntervalPlot class to draw the 2D contour.
- New tutorials have been added: rs501_ProfileLikelihoodCalculator_limit.C and rs502_ProfileLikelihoodCalculator_significance.C for getting the interval limits and significance using the ProfileLikelihoodCalculator. The tutorials can be run on a set of Poisson data or Gaussian over flat with model considering optionally the nuisance parameters. The data can be generated with the rs500 tutorials.
HybridCalculator
- In the constructor the signature passing a name and a title string has been removed, for being consistent with all the other calculator classes. Name and title can be set optionally using the SetName and SetTitle methods. Please note that this change is not backward compatible.
- Add the option to use binned generation (via SetGenerateBinned).
- An estimated of the error in the obtained p values is now computed in the HybridResult class thanks to Matthias Wolf. The errors can be obtained with HybridResult::CLbError(), HybridResult::CLsplusbError() or HybridResult::CLsError().
- A new tutorial has been added for showing the usage of the hybrid calculator: rs505_HybridCalculator_significance.C
new class HypoTestInverter
- New class for performing an hypothesis test inversion by scanning the hypothesis test results of the HybridCalculator for various values of the parameter of interest. An upper (or lower) limit can be derived by looking at the confidence level curve of the result as function of the parameter of interest, where it intersects the desired confidence level.
- The class implements the IntervalCalculator interface and returns an HypoTestInverterResult class. The result is a SimpleInterval, which via the method UpperLimit returns to the user the upper limit value.
- The HypoTestInverter implements various option for performing the scan. HypoTestInverter::RunFixedScan will scan using a fixed grid the parameter of interest. HypoTestInverter::RunAutoScan will perform an automatic scan to find optimally the curve and it will stop when the desired precision is obtained. The confidence level value at a given point can also be done via HypoTestInverter::RunOnePoint.
- The class can scan the CLs+b values (default) or alternatively CLs (if the method HypoTestInverter::UseCLs has been called).
- The estimated error due to the MC toys statistics from the HybridCalculator is propagated into the limits obtained from the HypoTestResult
- A new tutorial rs801_HypoTestInverter.C has been added in the tutorials/roostats directory to show the usage of this class.
New class BayesianCalculator
- New class for calculating Bayesian interval using numerical integration. It implements the IntervalCalculator interface and returns as result a SimpleInterval.
- The BayesianCalculator::GetInterval() method returns a SimpleInterval which contains the lower and upper value of the bayesian interval obtained from the posterior probability for the given confidence level.
- The class return also the posterior pdf (BayesianCalculator::GetPosteriorPdf()) obtained from integrating (marginalizing) on the nuisance parameters.
- It works currently only for one-dimensional problems by relying on RooFit for performing analytical or numerical integration.
- A plot of the posterior and the desired interval can be obtained using BayesianCalculator::GetPosteriorPlot().
- A new tutorial rs701_BayesianCalculator.C has been added in the tutorials/roostats directory to show the usage of this class.
MCMCCalculator
- Add possibility to specify the prior function in the constructor of the class to have a signature similar to the BayesianCalculator class. When no prior is specified it is assumed is part of the global model (pdf) passed to the class.
Improvements and Bug fixes
- Various improvements and fixes have been applied also to all the calculator classes. Internally now the RooArgSet objects are used by value instead of a pointer.
- All the calculator have a consistent way for being constructed, either by passing pdf pointers and the set defining the parameters or by passing a reference to a ModelConfig class.
- The result classes are now more consistent and have similar constructors. In addition to a default constructor, all of them can be constructed by passing first a name and then all the quantities (objects or values) needed for the specific result type. The title can eventually be set using the SetTitle method inherited from TNamed.
TMVA
TMVA version 4.0.4 is included in this root release.Methods
- A new Category method allowing the user to
separate the training data (and accordingly the application
data) into disjoint sub-populations exhibiting significantly
different properties. The separation into phase space regions is
done by applying requirements on the input and/or spectator
variables. In each of these disjoint regions (each event must
belong to one and only one region), an independent training is
performed using the most appropriate MVA method, training
options and set of training variables in that zone. The division
into categories in presence of distinct sub-populations reduces
the correlations between the training variables, improves the
modelling, and hence increases the classification and regression
performance. Presently, the Category method works for
classification only, but regression will follow soon. Please
contact us if urgently needed.
An example scripts and data files illustrating how the new Category method is configured and used. Please check the macros test/TMVAClassificationCategory.C and test/TMVAClassificationCategoryApplication.C or the corresponding executables. - Regression functionality for gradient boosted trees using a Huber loss function.
Comments
On Input Data:
New TMVA event vector building. The code for splitting the input
data into training and test samples for all classes and the
mixing of those samples to one training and one test sample has
been rewritten completely. The new code is more performant and
has a clearer structure. This fixes several bugs which have been
reported by the TMVA users.
On Minimization:
Variables, targets and spectators are now checked if they are
constant. (The execution of TMVA is stopped for variables and
targets, a warning is given for spectators.)
On Regression:
The analysis type is no longer defined by calling a dedicated
TestAllMethods-member-function of the Factory, but with the
option "AnalysisType" in the Factory. The default value is
"Auto" where TMVA tries to determine the most suitable analysis
type from the targets and classes the user has defined. Other
values are "regression", "classification" and "multiclass" for
the forthcoming multiclass classification.
Missing regression evaluation plots for training sample were added.
On Cut method:
Removed obsolete option "FVerySmart" from Cuts method.
On MLP method:
Display of convergence information in the progress bar for MLP during training.
Creation of animated gifs for MLP convergence monitoring (please
contact authors if you want to do this).
On Datasets:
Checks are performed if events are unvoluntarily cut by using a
non-filled array entry (e.g. "arr[4]" is used, when the array
has not always at least 5 entries). A warning is given in that
case.
Bug fixes
- Spectators and Targets could not be used with by-hand assignment of events.
- Corrected types (training/testing) for assigning single events.
- Changed message from FATAL to WARNING when the user requests more events for training or testing than available.
- Fixed bug which caused TMVA to crash if the number of input variables exceeded the allowed maximum for generating scatter plots.
- Prevent TMVA from crashing when running with an empty TTree or TChain.
- A variable expression like "Alt$(arr[3],0)" can now be used to give a default value for a variable if for some events the array don't contain enough elements (e.g. in two jet events, sometimes only one jet is found and thus, the array jetPt[] has only one entry in that cases).
- Plot ranges for scatter-plots showing the transformed events are now correct.
- User defined training/testing-trees are now handled correctly.
- Fix bug in correlation computation for regression.
- Consistent use of variable labels (for the log output) and variable titles (in histograms).
- Drawing of variable labels in network architecture display for regression mode has been added.
- Bug fixes to Cuts which improves performance on datasets with many variables.
- Bug fix in GaussTransformation which improves handling of gaussian tails.
Geometry
MonteCarlo
GUI
TRootCanvas/TCanvas
- Implement tooltip displaying information about the primitive below the mouse pointer in a canvas.
It is possible to enable/disable this optional feature with the "Tooltip Info" menu entry from the "View" menu of the canvas.
To change the default behaviour (off by default), a new option has been added in system.rootrc:
Canvas.ShowToolTips: false
TBrowser
- Automatically switch to the tab containing the current canvas (if any) when e.g. drawing a histogram by double-clicking on its list tree item in a root file.
- Automatically switch to (and update) the list of files in the file browser (left panel) when opening a ROOT file from the "Open File" menu
TGListView
- Keyboard navigation is now fully working in the list view.
TGMainFrame
- Allow to save a snapshot of the GUI in a picture file. The supported formats are gif, jpg, png, tiff, and xpm.
TGFileDialog
- Allow to change directory by typing its name in the text entry field of the dialog
TProofProgressDialog
- Added a speedometer widget (TGSpeedo) to display the processing rate
- Added a check button to enable/disable smooth update of the speedometer (enabled by default). This could be useful in the case of slow displays (e.g. when using it via ssh)
- Several layout improvements
TRecorder
- Improvements and consolidation of the cross-platform interoperability, allowing to record and replay sessions between different platforms with less side effects. NB: Using different OS/WM (Window Managers) and using different ROOT GUI settings (via e.g. system.rootrc) between recording and replaying may still produce a wrong behavior of the recorder.
- New tutorial guitest_playback.C replaying a recorded session showing and validating the GUI (using guitest.C)
GUI Builder
New features, new user interface
Several important features have been added to the builder, and its user interface has been redesigned. Editing modes are now clearly distinguished with enabled and disabled layout mode. Possibility to enable automatic layout fasten the interface development, as the positioning doesn't have to be done manually anymoreMajor changes in the user interface:
- Added a list tree displaying the complete structure of the GUI
- The name of every element of the GUI is now editable
- New, more intuitive interface for padding and layout hints
- Color settings option was added to the widget editor
- Extended commands in the top menu (open project, save project...)
- Added important warning dialogs, such as "Save project" dialog when closing the window
- Added several tool tips
Graphical Output
PostScript and PDF
- In the following macro the minus sign was not correct:
{ TCanvas *c = new TCanvas; TLatex *l = new TLatex(0.5, 0.5, "#font[122]{a = b + c - d #pm e}"); l->Draw(); c->SaveAs("c.eps"); }The font 122 is the greek one. With a such TLatex "a" becomes "alpha", "b" becomes " beta" etc ... It is not the recommended way to do greek characters with TLatex, but it should work anyway. - In TPostScript::DrawPolyMarker: do not draw the markers is the marker size is 0.
- Right aligned or centered text was not correctly positioned when rotated.
TASImage
- The text size adjustment applied TASImage::DrawText
was not valid (scale factor of 1.044). The text size was wrong and the
following macro produced a wrong title when ran in batch:
{ TCanvas *canvas = new TCanvas("c5","c5",900,900); TH1F *histo = new TH1F("Histo","123456x_{i}abcdefy^{2}",100,0,20); canvas->Print("drawing.gif"); } - Suppress annoying messages like:
root : looking for image "filename" in path [/home/username/icons]printed by libAfterImage when using TImage::Open("filename") - In TImageDump the hollow filled areas were not correct:
- they used the line attributes,
- a line was drawn around the polygons filled with patterns.
Interface to graphviz
Thanks to three new classes (TGraphStruct, TGraphNode and TGraphEdge) ROOT provides an interface to the graphs visualization package graphviz. Graph visualization is a way of representing structural information as diagrams of abstract graphs and networks.Example:
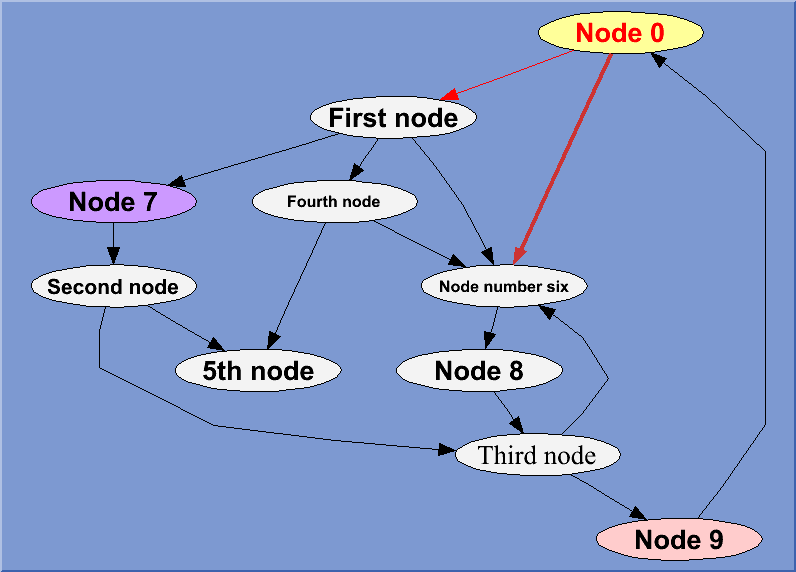
// Draw a simple graph structure.
// The graph layout is made using graphviz. This macro creates some
// nodes and edges and change a few graphical attributes on some of them.
// Author: Olivier Couet
{
TGraphStruct *gs = new TGraphStruct();
// create some nodes and put them in the graph in one go ...
TGraphNode *n0 = gs->AddNode("n0","Node 0");
TGraphNode *n1 = gs->AddNode("n1","First node");
TGraphNode *n2 = gs->AddNode("n2","Second node");
TGraphNode *n3 = gs->AddNode("n3","Third node");
TGraphNode *n4 = gs->AddNode("n4","Fourth node");
TGraphNode *n5 = gs->AddNode("n5","5th node");
TGraphNode *n6 = gs->AddNode("n6","Node number six");
TGraphNode *n7 = gs->AddNode("n7","Node 7");
TGraphNode *n8 = gs->AddNode("n8","Node 8");
TGraphNode *n9 = gs->AddNode("n9","Node 9");
n4->SetTextSize(0.03);
n6->SetTextSize(0.03);
n2->SetTextSize(0.04);
n3->SetTextFont(132);
n0->SetTextColor(kRed);
n9->SetFillColor(kRed-10);
n0->SetFillColor(kYellow-9);
n7->SetFillColor(kViolet-9);
// some edges ...
gs->AddEdge(n0,n1)->SetLineColor(kRed);
TGraphEdge *e06 = gs->AddEdge(n0,n6);
e06->SetLineColor(kRed-3);
e06->SetLineWidth(4);
gs->AddEdge(n1,n7);
gs->AddEdge(n4,n6);
gs->AddEdge(n3,n9);
gs->AddEdge(n6,n8);
gs->AddEdge(n7,n2);
gs->AddEdge(n8,n3);
gs->AddEdge(n2,n3);
gs->AddEdge(n9,n0);
gs->AddEdge(n1,n4);
gs->AddEdge(n1,n6);
gs->AddEdge(n2,n5);
gs->AddEdge(n3,n6);
gs->AddEdge(n4,n5);
TCanvas *c = new TCanvas("c","c",800,600);
c->SetFillColor(38);
gs->Draw();
return c;
}
This new funtionnality relies on the graphivz package.
This package can be downloaded from
http://www.graphviz.org/.
At installation time, to find graphviz, the ROOT's configure file looks in standard locations. It is possible to define a specific location using the configure flags:
--with-gviz-incdir="the directory where gvc.h is" --with-gviz-libdir="the directory where the libgvc library is"
To install graphviz (if needed) it is recommended to use the following configure flags:
--enable-static=yes --enable-shared=no --with-pic --prefix="graphviz installed here"
On 64 bits machines, the ROOT sources are compiled with the option -m64. In that case graphviz should be also compiled in 64 bits mode. It might be the default option, but on some machine it is not. In that case the environment variable CC should be defined as:
CC="gcc -m64"
before doing configure.
On Windows machines it recommended to not install graphviz but to download the pre-installed version from http://www.graphviz.org/. The ROOT configure command remains the same.
Graphics Primitives
New class TGraphTime
TGraphTime is used to draw a set of objects evolving with nsteps in time between tmin and tmax. each time step has a new list of objects. This list can be identical to the list of objects in the previous steps, but with different attributes. see example of use in $ROOTSYS/tutorials/graphs/gtime.CTLatex
- In the following macro the #int and #sum symbols had
wrong limits placement if the character just before started with "#".
{ TCanvas *c1 = new TCanvas("c1","c1",500,500); TLatex l; l.SetTextSize(0.1); l.DrawLatex(0.1,0.6,"#nu#int^{1-x}_{2#pi}"); l.DrawLatex(0.1,0.2,"a#int^{1-x}_{2#pi}"); l.DrawLatex(0.5,0.6,"#nu#sum^{1-x}_{2#pi}"); l.DrawLatex(0.5,0.2,"a#sum^{1-x}_{2#pi}"); }This problem is there since the 1st version of TLatex. It is fixed by:- Giving "^" and "_" a lower precedence than special and greek characters.
- Making a special case for #int and #sum and giving them even lower precedence than "^" and "_".
TMarker
- The markers picking now takes into account the marker size. This is useful for big markers, because there is no need to pick exactly the marker's center.
TPad
- It is now possible to zoom and unzoom axis using the mouse wheel.
TCanvas
- In DrawClonePad make sure that the cloned pad has the correct size even when the original pad has a toolbar and/or a status bar.
TPie
- TPie::GetEntryVal(i) returned GetSlice(i)->GetRadiusOffset() instead of GetSlice(i)->GetValue(). Very likely the code was copied/pasted from the method TPie::GetEntryRadiusOffset(i).
TGaxis
- An axis with a custom scale defined by a function did not display ticks all
the way along the axis, only between the lowest and the highest major tick.
This behaviour could be seen with:
{ TF1* f = new TF1("f", "exp(x)", 0.467, 2.1345); TGaxis* a = new TGaxis(0.1,0.4,0.9,0.4, "f", 50510, "-"); a->Draw(); TGaxis* b = new TGaxis(0.1,0.7,0.9,0.7, 0.4356, 1.56789, 50510, "-"); b->Draw(); }
Eve
Major changes
- Add support for hierarchical positioning of TEveElements in any specific scene. This allows for easier positioning of elements in dynamic scenes when child elements are attached to their parent elements and are supposed to follow their movements / rotations.
- Several significant improvements in TEveCaloLego classes.
- Calo classes now support individal tower selection. The selection is properly maintained across all views (3D / RPhi / RhoZ / Lego). See screenshot below.
- In top view draw cell values, if their screen size is above given limit.
- New energy-scales drawn as overlay (in color and size mode). The legend can be moved around the screen with the mouse.
- Fix transition between orthographic and perspective camera in TEveCaloLego event handler.
- Use color-sets in overlays and axis in order to automatically keep same contrast when changing background color.
- In TEveTrackPropagator improve overall trajectory extrapolation
through the path-marks. Fix a problem with path-mark / boundary
approach with near-zero magnetic field.
Maximum R / Z of extrapolation that can be set in the object editor can now be changed via static data-members fgEditorMaxR and fgEditorMaxZ. - Generalization of selection from GL viewers to support internal multiple selection from the elements.
- Add support for selection of individual calorimeter towers in TEveCalo classes.
- Add support for 3D -> 3D projections. This also allows for
scaling (compression/extension) of certain space region as required by
NA62 to show the 200m long detector in a meaningful way.
Several generalizations of the projection infrastructure were
required:
- TEveProjectable::ProjectedClass() takes an argument: virtual TClass* ProjectedClass(const TEveProjection* p) const = 0; thus allowing different projected classes for different projections.
- All TEveProjection::ProjectPoint/Vector(...) functions have an
additional "depth" argument thus allowing the projected classes to
skip explicit setting of depth after the point has been projected
-- this could damage the 3rd component.
Pre-scaling now supports 3 dimensions. - Abstract TEveProjected::SetDepth() has been split into two parts:
- It has been implemented in the base class where it checks for the projection type (2d) before calling the local function;
- Abstract SetDepthLocal() has been added to provide the same functionality.
- New projection class has been introduced: TEve3DProjection. It performs pre-scaling and offsets the center.
- To simplify the projection of lists TEveElementList has been made
projectable and corresponding TEveElementListProjected class
introduced. This also fixed the problem with render-state not being
propagated to projected classes.
The check whether to project a sub-tree of elements is still performed. - TEveGeoShapeProjected has been introduced to represent the 3D
projection of a TEveGeoShape (2D projection is handled by
TEvePolygonSetProjected).
Points, lines and tracks use the same projected class for both 2D and 3D projections.
- TEveManager now allows simultaneous usage of several objects editors. Simply click on the top name-button in object editor to create a standalone editor for this object in a separate window. This facilitates operation when several objects need to be modifed in parallel.
- New tutorial alice_vsd.C has been added. It shows how to read Visualization Summary Data files (VSD).
- Code for operating three view configuration (3D / RPhi / Rhoz) has been extracted from alice_esd.C tutorial into MultiView.C tutorial. This is now also used by alice_vsd.C and can serve as an example to those that need to implement similar functionality.


Minor changes
- Object editors in Eve now show the title as button.
- Left mouse opens a floating editor that can be positioned anywhere on the screen. This allows a user to have commonly used editors always accessible. Maximum number of floating editors is limited to 10.
- Right mouse opens context menu for the object.
- In TEveFrambox add support for drawing of back-polygons for 3D frame-boxes. Those should be transparent, otherwise the things inside are not visible.
- TEveRGBAPalette - implement additional flag fFixColorRange specifying
how the palette color range gets mapped onto signal values:
- true - LowLimit -> HighLimit
- false - MinValue -> MaxValue.
- Add signal emitting TEveRGBAPalette::MinMaxValChanged(). Ged editor calls this after setting the min/max range.
OpenGL
Major changes
- Add support for stereo rendering. This requires quad buffer support from OpenGL driver and hardware as well as shutter glasses. See tutorial eve/geom_cms_stereo.C.
- Support for rendering into frame-buffer objects (FBO).
- Using FBOs, it is now possible to save bitmap image formats at any resolution and even when the GL window is not on screen.
- Add support for global scaling of point-sizes, line-widths and font-sizes.
- Generalize secondary-selection handling so that it is possible to implement various handling schemes. For example see individual calorimeter tower selection in TEveCalo-classes.
- Generalize handling of highlight feedback -- this is now done via a virtual TGLLogicalShape::DrawHighlight(...) so that it can be changed by sub-classes.
- The stand-alone GL viewer now supports hiding of menu-bar. It collapses into a narrow band on top of the viewer that expands when mouse pointer enters its area. This allows for better utilization of the screen while still providing the controls available from the menu.
- Editor for "gl5d" option was improved.
- TGLTH3Composition class to combine several TH3s in one plot.
Minor changes
- Use Diagonal() instead of Volume() to determine if a bounding-box is empty and also for sorting of the scene-elements by size. The previous implementation caused problems with 2D and 1D objects.
- Several improvements in camera configuration and handling.
- Improve mouse-button handling. After a button goes down, other buttons do not interfere with user interaction until the first button is released.
- When initializing TGLClipPlane for the first time, place it in the center of the scene's bounding-box. Before that, plane was always positioned at (0,0,0) which lead to unexpected behaviour when scene was not centered at the origin.
- Add virtual function TGLClip::Setup(const TGLVector3&, const TGLVector3&) and implement it for plane and box clipping objects. See function documentation for TGLClipPlane and TGLClipBox.