ROOT Version 5.28/00 Release Notes
ROOT version 5.28/00 has been released on December 15 2010. In case you are upgrading from an old version, please read the releases notes of version 5.16, 5.18, 5.20, 5.22, 5.24 and version 5.26 in addition to these notes.
- Bindings - packages related to the interplay with other programming languages (Python, Ruby)
- Cint - the C++ interpreter
- Core - the basic ROOT functionality
- Geometry - building, representing and drawing geometrical objects
- 2D Graphics - ROOT's two dimensional graphics interface
- 3D Graphics - ROOT's three dimensional graphics interface
- Graphical User Interface - from basic GUI elements to ROOT's own, complete dialogs
- Histograming - counting values, spectra, and drawing them
- HTML - the documentation generator
- Input/Ouput - storing and reading data
- Mathemathics - everything one can use to calculate: minimizers, matrixes, FFT, and much more
- Miscellaneous - things that didn't make it into the other groups: table
- Monte Carlo - monte carlo and physics simulation interfaces
- Networking - network-related parts, e.g. protocols and authentication interfaces
- PROOF - parallel ROOT facility
- RooFit - a fitting library
- RooStats - a collection of statistical tools
- SQL - database interfaces
- TMVA - multivariate analysis tools
- Trees - ROOT's unique container class and related utilities
- Tutorials - ROOT's Tutorials
Binaries for all supported platforms are available at:
http://root.cern.ch/drupal/content/production-version-528
For more information, see:
http://root.cern.ch
The following people have contributed to this new version:
Alberto Annovi, INFN, TH1,
Kevin Belasco, Princeton University, RooStats,
Bertrand Bellenot, CERN/SFT,
Rene Brun, CERN/SFT,
Philippe Canal, FNAL,
Olivier Couet, CERN/SFT,
Kyle Cranmer, NYU, RooStats,
Jason Detwiler, LBL, TClonesArray,
Valeri Fine, BNL/STAR,
Fabrizio Furano, CERN/IT,
Gerri Ganis, CERN/SFT,
Andrei Gheata, CERN/Alice,
Oleksandr Grebenyuk, GSI, TLatex, TPostScript,
Christian Gumpert, CERN and University Dresden, TEfficiency
Bill Heintzelman, UPENN, TTree,
Andreas Hoecker, CERN/Atlas, TMVA,
Pierre Juillot, IN2P3, PostScript,
Folkert Koetsveld, Nijmegen, RooFit,
Alex Koutsman, Nikhef, RooFit,
Sven Kreiss, NYU, RooStats,
Wim Lavrijsen, LBNL, PyRoot,
Sergei Linev, GSI,
Benno List, Desy, MathCore and MathMore,
Anar Manafov, GSI,
Mike Marino, TUM, pyroot/tutorials
Ramon Medrano Llamas, University of Oviedo, PROOF
Biagio di Micco, Pythia8,
Lorenzo Moneta, CERN/SFT,
Axel Naumann, CERN/SFT,
Eddy Offermann, Renaissance,
Bartolomeu Rabacal, CERN/ADL, Math,
Fons Rademakers, CERN/SFT,
Paul Russo, FNAL,
Sangsu Ryu, KISTI, PROOF
Stefan Schmitt, Desy, TUnfold,
Gregory Schott, Karlsruhe/CMS, RooStats,
Benoit Speckel, IN2P3, Fonts,
Peter Speckmayer, CERN, CLIC, TMVA,
Joerg Stelzer, DESY/Atlas, TMVA,
Alja Tadel, CERN/CMS, Eve,
Matevz Tadel, CERN/Alice, Eve,
Jan Therhaag, University Bonn, ATLAS, TMVA,
Eckhard von Toerne, University Bonn, ATLAS, TMVA,
Wouter Verkerke, NIKHEF/Atlas, RooFit,
Helge Voss, MPI Heidelberg, LHCb, TMVA
Core
Build system and Platform support
- The build system has been extended to support out-of-source builds.
This means you can build different sets of binaries from one source tree, like:
mkdir root-debug cd root-debug ../root/configure --build=debug - The build system now supports cross compilation, where typically you need tools like rootcint, rootmap, etc, to be compiled on the build platform to be able to generate dictionaries for the target platform.
- ROOT has been ported to iOS. This port required the above mentioned
changes in the build system. To build ROOT for the iPhone/iPad sumilator do:
./configure iossim makeTo build a native iOS armv7 version do:./configure ios makeBoth builds create a libRoot.a that can be used to create ROOT based iOS apps (iOS does not allow apps to load non-system dynamic libraries at run time). Some sample Xcode projects using ROOT will soon be made available.
Base
- Change TTime data member from Long_t to Long64_t. On 32-bit systems the
Long_t is 32-bits and too small to keep the time in milliseconds since the ROOT EPOCH (1-1-1995). Added new operators:
operator long long() operator unsigned long long()
The existing operators long and unsigned long on 32-bit machines return an error in case the stored time is larger then 32-bit and truncation occurs (like was always the case till now, but silently). - New method ExitOnException() which allows to set the behaviour of TApplication in case of an exception (sigsegv, sigbus, sigill, sigfpe). The default is to trap the signal and continue with the event loop, using this method one can specify to exit with the signal number to the shell, or to abort() which in addition generates a core dump.
- New command line argument -x which forces ROOT to exit on an exception.
- Add TSystem::AddDynamicPath.
Build
- New option '-t' for rmkdepend to allow the caller to fully specify the name to be used as a target This supersedes the name calculated from the input file name and the -p and -o option.
ACLiC
- Allow ACLiC to use a flat directory structure when a build directory is specified.
To use a flat structure do:
gSystem->SetBuildDir(whereIwant, kTRUE); // the default for the 2nd parameter is kFALSE
Or use '-' in the option of CompileMacrogSystem->CompileMacro(myscript,"k-",...);
Meta
- Implement polymorphism for Emulated object (still not supporting polymorphism
of Emulated Object inheriting from compiled class).
This avoids memory leaks when the user data model relies on polymorphism
and does not the shared library defining the classes theand avoid splicing if the data is copied.
TStreamerInfo::New inserts the address of the creating TStreamerInfo into the object. This address is inserted in each emulated that does not inherit from an emulated class and is positioned after all the base classes (which are compiled classes). A derived class will set this value inside each of its emulated base class.
TStreamerInfo::Destruct and the new method TStreamerInfo::GetActualClass use this information to detect the TStreamerInfo actually used to create the object and hence run the proper emulated destructor. - Add a new function GenerateDictionary to TInterpreter which allows for the quick and easy creation of a dictionary
given one (or more) class name(s) and the name(s) of its header files.
gInterpreter->GenerateDictionary("vector<vector<float> >;list<vector<float> >","list;vector"); gInterpreter->GenerateDictionary("myclass","myclass.h;myhelper.h");This replaces the recommendation of creating a small 'loader.C' script to create the dictionaries. - Implement a ShowMembers function for interpreted classes, by querying the interpreter for the data member information.
- In order to fix possible buffer overflow of parent string buffer in TMemberInspector, the signature of ShowMember() was changed to no longer require (nor request) the caller to provide a buffer (of length unknown to the callee.)
- Improve the uniqueness of globally visible symbols to allow for the mixing of dictionaries with very similar layout.
Cont
- New functions for TClonesArray:
- AbsorbObjects(TClonesArray* otherTCA): Allows one to directly move the object pointers from otherTCA to the calling TCA without cloning (copying). The calling TCA takes over ownership of all of the moved objects. otherTCA is left empty upon return.
- MultiSort(Int_t nTCs, TClonesArray** tcs): Sorts multiple TClonesArrays simultaneously using the calling TCA's objects as the sorting key.
- New function for TSeqCollection: QSort(Object **a, Int_t nBs, TObject ***b): Sort array a of TObject pointers using a quicksort algorithm. Arrays b will be sorted just like a (a determines the sort; nBs is the number of TObject** arrays in b). Uses ObjCompare() to compare objects. This function is used by the new function TClonesArray::MultiSort().
- Add a new option "+" in TClonesArray::Clear. When the option starts with "C+", eg "C+xyz" the objects in the array are in turn cleared with the option "xyz".
- Since the Collection objects do have a name and the Clone method does allow for the name to change, TCollection::Clone was added to implement the name change properly.
Thread
- New static function TThread::IsInitialized
I/O
File Format
- The default for streaming the content of STL containers was changed from object-wise
to member-wise.
We evaluated the impact of moving to MemberWise streaming using 5 different CMS data files:
- cms1.root an older split using level 99 Reco file
- cms2.root a more recent non split raw data file
- cms3.root a more recent non split Reco file
- cms4.root is an example of the lepton plus jet analysis format known as a user PAT-tuple (split)
- cms5.root is an example AOD (analysis object dataset) format file. It is not split because the objects here are a strict subset of the RECO objects.
Split files Filename Memberwise Size Cpu Time To read cms1.root N 17.5 Gb 10.55s +/- 0.15 (2200 entries) cms1.root Y 16.8 Gb 9.12s +/- 0.08 (2200 entries) cms4.root N 1.47 Gb 10.18s +/- 0.19 (2500 entries) cms4.root Y 1.43 Gb 9.24s +/- 0.06 (2500 entries) Non Split files Filename Memberwise Size Cpu Time To read cms2.root N 1.65 Gb 10.95s +/- 0.05 (1000 entries) cms2.root Y 1.53 Gb 8.20s +/- 0.05 (1000 entries) cms3.root N 0.780 Gb 10.59s +/- 0.05 (700 entries) cms3.root Y 0.717 Gb 8.29s +/- 0.08 (700 entries) cms5.root N 1.55 Gb 10.20s +/- 0.17 (700 entries) cms5.root Y 1.40 Gb 8.09s +/- 0.08 (700 entries) - In the case of a data member which is a pointer to a STL container, eg:
std::container<Data> *fDataObjects;
and which is stored member-wise, add support for the schema evolution of the class 'Data'.
This requires a change in the on file format used to store this type of data members (i.e. by adding inline the version number of the class 'Data').
To read file containing this construct and written with this revision using an older version of ROOT you will need the following patches:- For v5.22/00, you will need the patch r33174 or v5.22/00k
- For v5.26/00, you will need patch r33176 or v5.26/00c
Run time performance
We introduced an optimized infrastructure for reading objects using a StreamerInfo. Rather than driving the streaming using a switch statement inside TStreamerInfo::ReadBuffer, the streaming is now driven using a simple loop over a sequence of configured StreamerInfo actions. This improves run-time performance by allowing a dramatic reduction in function calls and code branches at the expense of some code duplication. There are 3 versions of this loop implemented in TBufferFile and overloaded in TBufferXML and TBufferSQL:- virtual Int_t ReadSequence(const TStreamerInfoActions::TActionSequence &sequence, void *object);
- virtual Int_t ReadSequenceVecPtr(const TStreamerInfoActions::TActionSequence &sequence, void *start_collection, void *end_collection);
- virtual Int_t ReadSequence(const TStreamerInfoActions::TActionSequence &sequence, void *start_collection, void *end_collection);
TBufferXML and TBufferSQL overload the loops to introduce extra code to help the buffer keep track of which streamer element is being streamed (this functionality is not used by TBufferFile.)
A TStreamerInfoActions::TActionSequence is an ordered sequence of configured actions.
A configured action has both an action which is a free standing function and a configuration object deriving from TStreamerInfoActions::TConfiguration. The configuration contains information that is specific to the action but varies from use to use, including the offset from the beginning of the object that needs to be updated. Other examples of configuration include the number of bits requested for storing a Double32_t or its factor and minimum.
When the sequence is intended for a collection, the sequence has a configuration object deriving from TStreamerInfoActions::TLoopConfiguration which contains for example the size of the element of a vector or the pointers to the iterators functions (see below).
Each TStreamerInfo has 2 reading sequences, one for object-wise reading (GetReadObjectWiseActions) and one for member-wise reading (GetReadMemberWiseActions) which is used when streaming a TClonesArray of a vector of pointer to the type of objects described by the TClass.
Each collection proxy has at least one reading sequences, one for the reading each version of the contained class layout.
Each case of the TStreamerInfo::ReadBuffer switch statement is replaced by 4 new action functions, one for the object wise reading, one for the member wise reading for TClonesArray and vector of pointers, one for the member wise reading for a vector of object and one for all other collections.
Each collection (proxy) needs to provide 5 new free standing functions:
// Set of functions to iterate easily throught the collection static const Int_t fgIteratorArenaSize = 16; // greater than sizeof(void*) + sizeof(UInt_t) typedef void (*CreateIterators_t)(void *collection, void **begin_arena, void **end_arena); virtual CreateIterators_t GetFunctionCreateIterators(Bool_t read = kTRUE) = 0; // begin_arena and end_arena should contain the location of a memory arena of size fgIteratorSize. // If the collection iterator are of that size or less, the iterators will be constructed in place in those location (new with placement) // Otherwise the iterators will be allocated via a regular new and their address returned by modifying the value of begin_arena and end_arena. typedef void* (*CopyIterator_t)(void *dest, const void *source); virtual CopyIterator_t GetFunctionCopyIterator(Bool_t read = kTRUE) = 0; // Copy the iterator source, into dest. dest should contain the location of a memory arena of size fgIteratorSize. // If the collection iterator is of that size or less, the iterator will be constructed in place in this location (new with placement) // Otherwise the iterator will be allocated via a regular new and its address returned by modifying the value of dest. typedef void* (*Next_t)(void *iter, const void *end); virtual Next_t GetFunctionNext(Bool_t read = kTRUE) = 0; // iter and end should be pointers to respectively an iterator to be incremented and the result of collection.end() // If the iterator has not reached the end of the collection, 'Next' increment the iterator 'iter' and return 0 if // the iterator reached the end. // If the end was not reached, 'Next' returns the address of the content pointed to by the iterator before the // incrementation ; if the collection contains pointers, 'Next' will return the value of the pointer. typedef void (*DeleteIterator_t)(void *iter); typedef void (*DeleteTwoIterators_t)(void *begin, void *end); virtual DeleteIterator_t GetFunctionDeleteIterator(Bool_t read = kTRUE) = 0; virtual DeleteTwoIterators_t GetFunctionDeleteTwoIterators(Bool_t read = kTRUE) = 0; // If the size of the iterator is greater than fgIteratorArenaSize, call delete on the addresses, // Otherwise just call the iterator's destructor.
TFile::MakeProject
-
Extend TFile::MakeProject to support genreflex, cases of user's data model where
the 2 distincts pointers point to a single object and more cases where we are
missing the StreamerInfo and need to guess whether the symbol represent an enum,
a class or a namespace.
To use genreflex, call MakeProject with the "genreflex" option, for example:
file->MakeProject(libdir,"*","NEW+genreflex");
-
To make sure the library created by MakeProject does not double delete an object,
tell the StreamerElement representing one of the pointers pointing to the object
to never delete the object. For example:
TClass::AddRule("HepMC::GenVertex m_event attributes=NotOwner"); - MakeProject now implements a move constructor for each classes. For the implementation, we 'use' the 'copy constructor' until the C++ compilers properly support the official move constructor notation. Implementing a move constructor avoid having to delete and reconstruct resource during a std::vector resize and avoid the double delete induced by using the default copy constructor.
- MakeProject now adds dictionaries for auto_ptr.
- MakeProject no longer request the dictionary for std::pair instances that already have been loaded.
Misc.
- TFile::Open now does variable expansion so that you can include the protocol in the variable (for example:
export H1="http://root.cern.ch/files/h1" ... TFile::Open("$H1/dstarmb.root"); - Added warning if the file does contain any StreamerInfo objects and was written with a different version of ROOT.
- Implemented polymorphism for Emulated object (still not supporting polymorphism of Emulated Object inheriting from compiled class). See the Core/Meta section for details.
- Add support for streaming auto_ptr when generating their dictionary via rootcint
- Enable the use of the I/O customization rules on data members that are either a variable size array or a fixed size array. For example:
#pragma read sourceClass = "ACache" targetClass = "ACache" version = "[8]" \ source = "Int_t *fArray; Int_t fN;" \ target = "fArray" \ code = "{ fArray = new Char_t[onfile.fN]; Char_t* gtc=fArray; Int_t* gti=onfile.fArray; for(Int_t i=0; i<onfile.fN; i++) *(gtc+i) = *(gti+i)+10; }" #pragma read sourceClass = "ACache" targetClass = "ACache" version = "[8]" \ source = "float fValues[3]" \ target = "fValues" \ code = "{ for(Int_t i=0; i<3; i++) fValues[i] = 1+onfile.fValues[i]; }" - Allow the seamless schema evolution from map<a,b> to vector<pair<a,b> >.
- Avoid dropping information when reading a long written on a 64 bits platforms and being read into a long long on a 32 bits platform (previously the higher bits were lost due to passing through a 32 bits temporary long).
- Migrate the functionality of TStreamerInfo::TagFile to a new interface TBuffer::TagStreamerInfo so that TMessage can customize the behavior. TMessage now relies on this new interface instead of TBuffer::IncrementLevel.
- New option to hadd, -O requesting the (re)optimization of the basket size (by avoid the fast merge technique). The equivalent in TFileMerger is to call merger->SetFastMethod(kFALSE)
- To make sure that the class emulation layer of ROOT does not double delete an object,
tell the StreamerElement representing one of the pointers pointing to the object
to never delete the object. For example:
TClass::AddRule("HepMC::GenVertex m_event attributes=NotOwner"); - The handling of memory by the collection proxy has been improved in the case of a
collection of pointers which can now become owner of its content.
The default, for backward compatibility reasons and to avoid double delete (at the expense
of memory leaks), the container of pointers are still not owning their content
unless they are a free standing container (i.e. itself not contained in another
object).
To make a container of pointers become owner of its content do something like:
TClass::AddRule("ObjectVector<LHCb::MCRichDigitSummary> m_vector options=Owner"); - Added TKey::Reset and TKey::WriteFileKeepBuffer to allow derived classes (TBasket) to be re-use as key rather than always recreated.
- TH1::Streamer and TGraph2D::Streamer no longer reset the kCanDelete bit directly so that the user can give ownership of the object to the canvas they are stored with. However, if they are saved on their own, the mechanism that associates them to the current directory (DirectoryAutoAdd) will now reset the bit to avoid any possible ownsership confusion.
- Added TFile::SetOffset and TFile::ReadBuffer(char *buf, Long64_t pos, Int_t len); to drastically reduce the number of fseek done on the physical file when using the TTreeCache.
- To support future changes in the API of the CollectionProxy, we added the new #define: ROOT_COLLECTIONPROXY_VERSION and REFLEX_COLLECTIONPROXY_VERSION
- Reduce possible confusions and conflicts by always using in TClass and TStreamerInfo the version of template instance names with ULong64_t and Long64_t rather than [unsigned] long long.
- new Hadoop TFile plugin.
Networking
- Xrootd
- New version 20100913-0630 including several consolidation fixes (many due to Coverity reports) and includes the new Bonjour/Avahi interface used for worker autodiscovery in PROOF.
- TMessage and TSocket
-
TMessage now relies on the new interface TBuffer::TagStreamerInfo instead of TBuffer::IncrementLevel which had the disadvantage of being called not only
during writing but also during reading (where there is no need to keep track of the TStreamerInfo used).
This change allows to keep the calls to IncrementLevel/DecrementLevel only in the case the buffer is a TBufferXML. - The implementation of TSocket::RecvStreamerInfos has been fixed to properly handle the case where there are abstract classes (in this case GetStreamerInfo() can not be called on the abstract class until it has been called during the processing of one of the concrete derived classes) and the case of STL containers.
-
TMessage now relies on the new interface TBuffer::TagStreamerInfo instead of TBuffer::IncrementLevel which had the disadvantage of being called not only
during writing but also during reading (where there is no need to keep track of the TStreamerInfo used).
SQL
Tree
- Introduce TBranch::Set/GetMakeClass to independently set each branch in MakeClass mode and to have a good place to switch the ReadLeaves function appropriately (to and from the MakeClass mode (also known as the decomposed object mode)). This can also be used to reset the mode of some branch with a MakeClass/MakeSelector file.
- Dramatically reduce the amount of memory allocation induces by the management of the TBasket and TBuffer for each branch. Instead of creating one TBasket object and one TBuffer object and its associated memory buffer for each onfile basket of each branch, we now create only one TBasket and one TBuffer object for the lifetime of each branch. The memory buffer associated with the TBuffer object is also created once and rarely reallocated; it is reallocated only when the buffer size is reset (for example by the AutoFlush mechanism) and when the user object do not fit in the currently allocated memory (but we do not shrink it after that. The same minization is applied to the scratch area used to read the compressed version of a basket from the file.
- In TTree and TChain's LoadTree fReadEntry is now set to -1 in case of failure to find the proper row.
- In TTree::CloneTree, TChain::Merge and TTree::CopyEntries introduces more flexibility
in the handling of the case where a TTreeIndex is 'missing' in one or more of the
TTree objects being collated. If the tree or any of the underlying tree of the chain has an index,
that index and any index in the subsequent underlying TTree objects will be merged. There are currently three 'options'
to control this merging:
- NoIndex : all the TTreeIndex object are dropped.
- DropIndexOnError : if any of the underlying TTree object do no have a TTreeIndex, they are all dropped.
- AsIsIndexOnError [default]: In case of missing TTreeIndex, the resulting TTree index has gaps.
- BuildIndexOnError : If any of the underlying TTree object do no have a TTreeIndex, all TTreeIndex are 'ignored' and the mising piece are rebuilt.
- In TBranch CopyAddress (and hence indirectly in the fast cloning) avoid having to read the first entry just to get the address set and do the address setting directly.
- In TTree::CopyAddress when copying the addresses of a branch created by a leaflist and where the memory buffer was allocated automatically (as opposed to set by the user) avoid deleting the memory allocated by the tree each time CopyAddress is called. (This effectively prevented cloning more than once a TTree with a branch created by a leaflist.)
- Warning: The TTreeCache is no longer enabled by default in a TChain to align the behavior with a TTree. You need to call TTree::SetCacheSize to enable the TTreeCache.
- Correct and clarify the relationship between AutoFlush and AutoSave:
- Both the AutoFlush and AutoSave interval can be specified in terms of bytes (a negative value for fAutoFlush or fAutoSave) or in terms of the number of entries (positive values).
- An AutoFlush is always done with an AutoSave.
- If the interval specified for AutoSave is less than that for AutoFlush, the AutoSave interval is used for both.
- If the AutoFlush interval is less than the AutoSave interval, the AutoSave interval is adjusted to the largest integer multiple of the AutoFlush interval that is less than or equal to the original value of the AutoSave interval.
- Update MakeProxy so that the resulting skeleton is useable with Proof.
- Update MakeProxy, MakeClass and MakeSelector to support more cases of branches names (that includes characters illegal in a C++ symbol)
- Replace the ReadLeaves virtual function by a fReadLeaves pointer to member function, this allows the customization of the ReadLeaves function at run-time depending on the underlying user class layout in TBranchElement. This removes many if statements whose 'answer' is known at initialization time.
- Add support for 'array' formula in TTree::Query.
- Set the initial value of fCacheSize to zero to indicate clearly that the TreeCache is disabled.
- In TChain::SetEntryList use only the treename to lookup the (sub)entryList (instead subdir/treename).
- Add support for the branch creation syntax:
TString rootString; t->Branch("rootString","TString",&rootString, 1600, 0);which is 'natural' as it uses the legacy syntax (branch_name,class_name, user_data) but did not work because 'rootString' is an object rather than a pointer to an object. (However the simplier form:t->Branch("rootString",&rootString, 1600, 0);works/worked fine). - Add type information to the result of TTree::Print in the case of
TBranchElement:
*Br 17 :fH : TH1F* * *Entries : 20 : Total Size= 19334 bytes File Size = 1671 * *Baskets : 2 : Basket Size= 16000 bytes Compression= 11.29 * *............................................................................* *Br 18 :fTriggerBits : TBits * *Entries : 20 : Total Size= 1398 bytes File Size = 400 * *Baskets : 1 : Basket Size= 16000 bytes Compression= 2.23 * *............................................................................* *Br 19 :fIsValid : Bool_t * *Entries : 20 : Total Size= 582 bytes File Size = 92 * *Baskets : 1 : Basket Size= 16000 bytes Compression= 1.00 *
- Add a new function TBranch::SetStatus It is much faster to call this function in case of a Tree with many branches instead of calling TTree::SetBranchStatus.
- Implement TTreeCache::Print that shows information like:
// ******TreeCache statistics for file: cms2.root ****** // Number of branches in the cache ...: 1093 // Cache Efficiency ..................: 0.997372 // Cache Efficiency Rel...............: 1.000000 // Learn entries......................: 100 // Reading............................: 72761843 bytes in 7 transactions // Readahead..........................: 256000 bytes with overhead = 0 bytes // Average transaction................: 10394.549000 Kbytes // Number of blocks in current cache..: 210, total size: 6280352
This function can be called directly from TTree: T->PrintCacheStats(); - Add support for variable size array of object in a TTree (when the owner of the array is split.)
- And many other bug fixes, security fixes, thread safety and performance improvements ; see the svn log for details.
TTree Scan and Draw
- Insured that the generated histogram as an integral bin width when plotting a string or integer.
- Improved the output of TTree::Scan by inserting a blank space whenever a value is not available because there is no proper row in a friend. (Previously it was re-printing the previous value). This required changes in
- When the draw option to TTree::Draw contains "norm" the output histogram is normalized to 1.
- Improve the selection of the leaf used for size of an array in a leaflist by giving preference
for the leaf inside the same branch and by adding support for explicit full path name. For example the following now works properly:
tree->Branch("JET1", &JET1, "njets/I:et[njets]/F:pt[njets]/F"); tree->BranchBranch("JET2", &JET2, "njets/I:et[njets]/F:pt[njets]/F"); ... tree->Scan("njets/I:et[JETS1.njets]/F:pt[JETS1.njets]");
Proof
- New functionality
- Add support for processing
many datasets in one go in TProof::Process(const char
*dataset, ...).
Two options are provided:
- 'grand dataset': the datasets are added up and considered as a single dataset (syntax: "dataset1|dataset2|...")
- 'keep separated': the datasets are processed one after the other; the user is notified in the selector of the change of dataset so she/he has the opportunity to separate the results. A new packetizer, TPacketizerMulti, has been developed for this case: it basically contains a list of standard packetizers (one for each dataset) and loops over them (syntax: "dataset1,dataset2,..." or dataset1 dataset2 ...").
In both cases, entry-list can be applied using the syntax "dataset<<entrylist", e.g. "dataset1<<el1|dataset2<<el2|".
The datasets to be processed can also be specified on one or multiple lines in a text file.
See http://root.cern.ch/drupal/content/working-data-sets for more details. - Add
support for automatic download of a package when available on the
master but not locally. The downloaded packages are store under <sandbox>/packages/downloaded
and automatically checked for updates against the master repository. If
a local version of the same package is created (using the
UploadPackage) the entry in downloaded is
cleared, so that the behaviour is unchanged.
The new functionality is described in http://root.cern.ch/drupal/content/working-packages-par-files . - Add the possibility to remap the server for the files in a dataset. This allows, for example, to reuse the dataset information for the same files stored in a different cluster.
- Add a local cache for TDataSetManagerFile. This is mainly used to improve the speed of TDataSetManager::ShowDataSets, which is run very often by users and may be very slow if the number of dataset is large. The cache is also used to cache frequently received dataset objects.
- Add the possibility to audit the activity on the nodes via syslog. See http://root.cern.ch/drupal/content/enabling-query-monitoring .
- New packetizer TPacketizerFile generating packets which contain a single file path to be used in processing single files. Used, for example, in tasks generating files. The files are specified into a TMap - named 'PROOF_FilesToProcess' - containing the list of files to be generated per host (the key is the host name, the value the TList of TObjString (or TFileInfo) with the files names - or a TFileCollection: the output of TFileCollection::GetFilesPerServer() can be directly passed as files map). Workers are first assigned files belonging to the list with host name matching the worker name. The map is distributed to the master via the input list.
- Add support for automatic setting of pointer data members to the relevant object in the output list. The use of fOutputList->FindObject("name") in TSelector::Terminate is not needed anymore for pointer data members, e.g. histograms.
- Add the possibility to define an external list of environment variables to be transmitted to the master and workers. This is done via the environment variable PROOF_ENVVARS. This addition allows to change the variables wthout changing the macro or application running TProof::Open. See http://root.cern.ch/drupal/content/controlling-environment-proof-session .
- Add the possibility to save the perfomance information shown
by the dialog into a small ntuple included in the output list. The
ntuple contains 5 floats (processing time, number of active workers,
event rate, MBytes read, number of effective sessions on the cluster)
and it is filled each time the number of active workers changes or at
max 100 regular intervals at least 5 secs apart; in this way the ntuple
has at most O(100 entries + number of workers). To enable the saving of
the ntuple execute the following:
proof->SetParameter("PROOF_SaveProgressPerf", "yes");
before running the query. The ntuple is called 'PROOF_ProgressPerfNtuple'. - Add support for worker autodiscovery in PROOF using the
Avahi/Bonjour technology. The new functionality is supported on Mac
(MacOsX >= 10.4; no need of additional installs) and linux (requires
the Avahi framework, available by default on most of the
distributions). To use this functionality (instead-of or in-addition-to
the the static worker configuration via proof.conf or xpd.worker) the
new directive 'xpd.bonjour' must be used (see description at
http://root.cern.ch/drupal/content/configuration-reference-guide#bonjour).
- Add support for processing
many datasets in one go in TProof::Process(const char
*dataset, ...).
- Improvements
- Improve support for valgrind runs in PROOF-Lite
- Add the possibility to add files to a dataset. This is achieved with a new option 'U' (for update) to RegisterDataSet.
- Add methof TProof::GetStatistics to allow the client to retrieve the correct values of fBytesRead, fRealTime and fCpuTime at any moment; this will be used to setup a sort of ROOTmarks in stressProof .
- Several improvements in the test program 'stressProof' and in the tutorials under 'tutorials/proof'
- Avoid contacting the DNS when initializing TProofMgr as base class of TProofMgrLite: it is not needed and it may introduce long startup delays.
- Make TProof::LogViewer("") start the viewer for a Lite session, in parallel to whats happen for TProof::Open("").
- Several improvements in the handling of wild cards in the dataset manager; for example, issuing a GetDataSet(...) on a dataset URI containign wild cards will return a grand dataset sum of all the datasets matching the URI.
- Add options to get a list of all dataset registered names from ScanDataSets (option kList; the result is a TMap of {TObjString, TObjString} with the second TObjString empty).
- Improved version of the PQ2 scripts; the scripts now invoke a dedicated ROOT application (named pq2) available under $ROOTSYS/bin .
- Add support for recursive reading of group config files via the 'include sub-file' directive. This allows to have a common part and, for example, customize differently the quotas.
- Fix an issue with TTreeFriends. New tutorial showing how to use friends in PROOF.
- Package management: add support for arguments in the SETUP function: it is possible now to pass a string or a list of objects. The TProof::EnablePackage interface has been extended to support this.
- Optimize the validation step in the case not all the entries are required. The validation step is stopped as soon as the requested number of events is reached. If the parameter "PROOF_ValidateByFile" is set to 1, the number of files is exactly what needed; otherwise the number of files may exceed the number of files needed by (Number_Of_Workers - 1) .
- New directive 'xpd.datadir' to better control the user data directories and their permission settings.
- In TPacketizerUnit, add the possibility to exactly share the number of cycles between the workers. See the parameter PROOF_PacketizerFixedNum.
- Implement a timer to terminate idle sessions. The timeout value is controlled by the variable ProofServ.IdleTimeout (value in seconds). This variable can be set for all sessions in the xproofd config file via the 'xpd.putrc' directive.
- Add the possibility to control the use of sub-mergers with
the ROOTrc variable Proof.SubMergers. It has the same meaning of the
parameter 'PROOF_UseMergers'. The capabilities of the latter have been
extended: now -1 means disable the use of submergers (before negative values were ignored and there was no way for the user to disable the use of submergers).
- Packetizer optimizations: improved worked distribution when the number of files left to be processed is smaller than the number of workers and at least one file has a number of events significantly larger than the average; better apply the upper/lower limits on the expected packet processing time.
- Add the possibility to single-out disk partitions in the
packetizer; this works adding the beginning of a path in the name
defining a new TFileNode (e.g. 'host://disk1' instead of 'host' only as
it was so far). These feature can be enabled by defining the rootrc
variable 'Packetizer.Partitions', e.g.
Packetizer.Partitions /disk1,/disk2,/disk3 - Add to the output list the parameters used by the active packetizer.
- In the PrintProgress function used to display a text progress bar, show also the average reading rate in [k,M,G}bytes/s in addition to the event processing rate. This is useful to have a feeling of the rate when running of a remote machine in batch mode.
- Add the possibility to control the resident and virtual memory of a proofserv using 'ulimit', which has less limitations and more flexibility than setrlimit.
- Deactivate workers when the requested packages could not be enabled properly.
- Add support for reconfiguring the group manager and the {env,rootrc} settings. The related configuration files are checked for changes during the regular checks done by the XrdProofdManager.
- Add support for selective definition of env and rootrc variables. Different values can be set for different users, groups, SVN versions or ROOT versions.
- Improve the diagnostic in case of exceptions. Information
about the event and file being processed at the moment the exception
was raised is sent to the client, e.g.
0.5: caught exception triggered by signal '1' while processing dset:'EventTree', file:'http://root.cern.ch/files/data/event_3.root', event:1 - check logs for possible stacktrace
The patch also fixes a problem with submergers observed when a worker was stopped because above the memory limits: this worker was established as merger but could not do the work, for obvious reasons, freezing the session. - Add two new methods to TProof: ShowMissingFiles() to facilitate
the display of the list of missing files; and GetMissingFiles() to get
a TFileCollection (dataset) with the missing files for further
processing.
- Fixes
- Fix a bug in error status transmission which avoid session freezing in some cases
- FIx a few issues in libXrdProofd.so with handling of connection used for admin operation: this should solve some cases where the daemon was not responding.
- Fix a few memory leaks showing up when running several queries in the same session
- Fix a few issues affecting the new sub-merging option
- Fix an issue preventing proper real-time notification during VerifyDataSet
- Fix an issue with TQueryResult ordering (was causing random 'stressProof' failures)
- Fix an issue with TProof::AskStatistics (fBytesRead, fRealTime and fCpuTime were not correctly filled on the client; the values on the master, displayed by TProof::Print were correct).
- Fix several small issues affecting the handling of global package directories
- Fix an issue with socket handling in the main event-loop while sendign or receiving files via TProofMgr.
- Fix a problem counting valid nodes in sequential or 'masteronly' mode, generating the fake error message "GoParallel: attaching to candidate!"
- Fix a few issues with the length of Unix socket paths affecting PROOF-Lite and xproofd on MacOsX
- Fix an issue with the release of file descriptors when recovering sessions .
- Fix an issue with a fake error message ("Error in <TROOT::cd>: No such file root:/") in PROOF-Lite when issuing TProof::SetParallel().
- Fix a problem with negative values for 'workers still sending' in PROOF-Lite .
- Fix locking issue while building packages locally.
- Fix issue setting permission and ownership of the dataset user directories.
- Fix a subtle bug affecting the (possibly rare) case when not all entries are required and # entries does not correspond to an complete subset of files (e.g. # entries = 1001000 with files of 100000 entries each). The effect was uncomplete processing (skipped events, magenta bar) or a session freeze.
- Fix problem with packet re-assignment in case of a worker death (some packets were processed twice or more times).
- Fix problem with the transmission of non-default file attributes (e.g. the number of entries) from TChainElement to TDSetElement during TChain processing in PROOF
- Fix problem in the default packetizer with validating the exact number of needed files when the information about the entries is already available.
- Fix problem with 'xpd.putenv' and 'xpd.putrc' occuring when the variables themselves contain commas.
- Avoid resolving the workers FQDN when running in PROOF-Lite, creating unnecessary delays when running PROOF-Lite within virtual machines.
- Fix problem with the permissions of the user data directory.
- Add files to the list of files to process only when finally validated.
- Fix problem with canvases when the feedback canvas and the final canvas are the same (do not delete the feedback canvas at the end of processing)
- Make sure that TProof::Load, TProofPlayer::SendSelector and TSelector::GetSelector treat consistently the extensions of the implementation files.
- Unlock the cache after failure to load a selector; prevents session freezing
- Correctly update the number of submergers when workers die
- Add missing protection causing a crash in submergers when the output list contained TProofOutputFile objects.
- Move the creation and start of the idle timeout from the end of SetupCommon to the end of CreateServer, so that the timeout is not active during worker setup.
- Make sure that the TProof instance on the client is invalidated after an idle timeout.
- Fix an old issue with DeactivateWorker("*") (the session is was terminated because no worker was active; this call coudl not be used as intermediate step to select a small number of workers).
- Consistently check both Proof.Sandbox and ProofLite.Sandbox for sandbox non-default location as done in TProofLite
- Fix a problem with the registration of missing files in the
'MissingFiles' list (files which could not be open on the workers were
not always added to the list).
Histogram package
TGraphDelaunay
- New version of the method TGraphDelaunay::Enclose(). This method
decides if a point is inside a triangle or not. The way it was implemented
produced infinite numbers and generated wrong peaks. It was visible on some
machines only (for instance MacOsX). Now this method uses
TMath::IsInside(). It is much safer, it runs faster, and the
code is simpler. The problem could be seen with a simple macro like the
following one:
{ TCanvas *c1 = new TCanvas("c1", "c1",0,0,600,600); c1->SetTheta(90.); c1->SetPhi(0.0001); gStyle->SetPalette(1); TGraph2D *graph2d = new TGraph2D(); graph2d->SetPoint(0, 110, 110, 0.0); graph2d->SetPoint(1, -80, 50, 1.0); graph2d->SetPoint(2, -70, 40, 2.0); graph2d->SetPoint(3,-110, -50, 3.0); graph2d->SetNpx(9); graph2d->SetNpy(9); graph2d->Draw("surf1"); graph2d->SetLineWidth(2); graph2d->Draw(" triw p0 same"); } - The X and Y vectors are normalized in order to compute the triangles. The scale factor used was the same for the X and Y axis. This generated problems (very long triangles instead of the obvious ones) in some cases when the X and Y axis had very different ranges. Having two scale factors, one for the X axis and one for the Y axis, cures the problem.
TGraph2D
- In case all the points are in the same Z-plane Z0 (zmin = zmax), the graph
minimum is set to Z0-0.01*Z0 and the maximum to Z0+0.01*Z0. This
allow to make TGraph2D like:
{ double *x = new double[2]; double *y = new double[2]; double *z = new double[2]; x[0] = 6215.; x[1] = 5542.; y[0] = 3853.; y[1] = 5270.; z[0] = 2723.; z[1] = 2723.; TGraph2D * g = new TGraph2D(2, x, y, z); g->Draw("LINE"); }
TGraph2DPainter
- When a TGraph2D was painted with the option TRI1 the color distribution in case of log scale along the Z axis was wrong.
THistPainter
- After executing the following macro, zooming the X axis interactively
generated the error message:
Error in <TGraphPainter::PaintGraphHist>: X must have N+1 values with option N{ int n = 70; TH1F h("h","test",n,0.,30.); TRandom3 rndm_engine; for (int i=0; i<10000; ++i) h->Fill(rndm_engine->Gaus(15.,4.)); TF1 f("f","gaus"); h->Fit("f"); gPad->SetLogx(); } - The following macro didn't draw any box. Because of a precision
problem the filled bin was not drawn.
{ double yarr[] = { 1.0, 2.0, 3.0, 4.0 }; double xarr[] = { 0.01, 0.02, 0.03, 0.04 }; TH2D *h = new TH2D("h","h",3,xarr,3,yarr); h->Fill(0.011,2.5); h->Draw("box"); } - The following macro displayed the histogram out of the frame
(option "bar"):
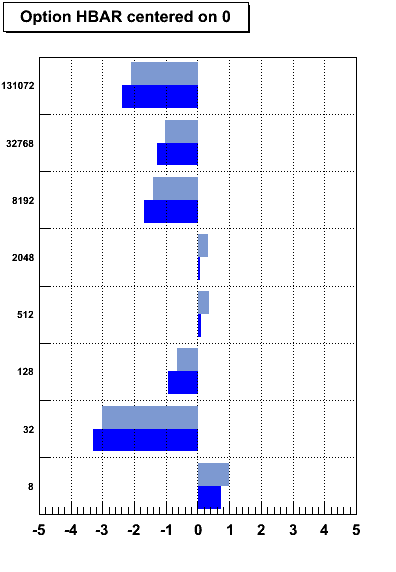
{ gStyle->SetHistMinimumZero(); TH1F* h = new TH1F("h","h", 44, -0.5, 43.5); h->SetBarWidth(0.7); h->SetBarOffset(0.2); h->SetFillColor(kGreen); for (int i=0;i<44; i++ ) h->Fill(i, -i-60); h->DrawCopy("bar1"); } - The setting gStyle->SetHistMinimumZero() now works for horizontal
plots produced with the option HBAR.
- In the case of profile histograms it is possible to print the number
of entries instead of the bin content. It is enough to combine the
option "E" (for entries) with the option "TEXT".
{ TCanvas *c02 = new TCanvas("c02","c02",700,400); c02->Divide(2,1); TProfile *profile = new TProfile("profile","profile",10,0,10); profile->SetMarkerSize(2.2); profile->Fill(0.5,1); profile->Fill(1.5,2); profile->Fill(2.5,3); profile->Fill(3.5,4); profile->Fill(4.5,5); profile->Fill(5.5,5); profile->Fill(6.5,4); profile->Fill(7.5,3); profile->Fill(8.5,2); profile->Fill(9.5,1); c02->cd(1); profile->Draw("HIST TEXT0"); c02->cd(2); profile->Draw("HIST TEXT0E"); }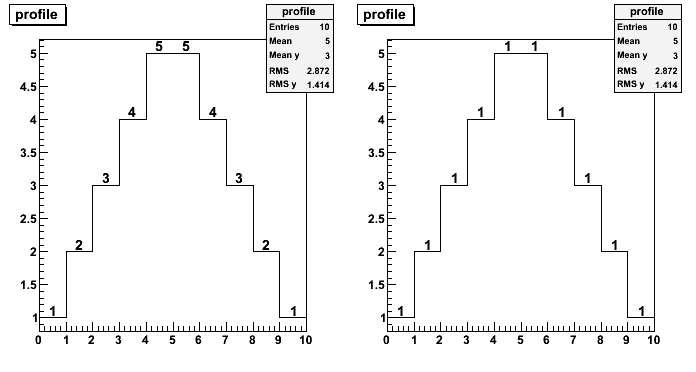
- The following lines generated an empty stats box:
gStyle->SetStatFont(43); gStyle->SetStatFontSize(12); TH2D *h2 = new TH2D("h2","h2",10,0,1,10,0,1); h2->Draw(); - PaintAxis does not redraw the axis labels and the axis title in case of axis redrawing. Only the tick marks are redrawn. Redrawing the labels and title made them appear a bit thicker.
- Fix a precision issue in PaintInit. The problem showed up with
the following lines:
TF1 *f = new TF1("f","exp(-x)*exp(x-2.)",0.,2.0); f->Draw(); - For 2D histograms plotted with option TEXT, it is possible to plot empty cells by calling gStyle->SetHistMinimumZero().
- An empty frame is drawn when an empty 1D histogram is painted with log scale along the Y axis and when a 2D histogram is painted with log scale along the Z axis.
- Log axis for TH3 histograms did not work.
- With option COL and SCAT, TH2 was drawn empty when all bins have the same content.
TGraphPainter
- When painted with option "2" (errors represented with boxes) the graph
with error bars were not clipped if the boxes were outside the frame
limits. This problem was visible with TGraphErrors, TGraphAsymmErrors and
TGraphBentErrors. The following macro showed the problem:
{ TCanvas *c1 = new TCanvas("c1","c1",200,10,700,500); const Int_t n = 10; Double_t x[n] = {-0.22, 0.05, 0.25, 0.35, 0.5, 0.61,0.7,0.85,0.89,0.95}; Double_t y[n] = {1,2.9,5.6,7.4,9,9.6,8.7,6.3,4.5,1}; Double_t ex[n] = {.05,.1,.07,.07,10.04,.05,.06,.07,.08,.05}; Double_t ey[n] = {3.8,.7,.6,.5,.4,.4,.5,.6,.7,.8}; Double_t exd[n] = {.0,.0,.0,.0,.0,.0,.0,.0,.0,.0}; Double_t eyd[n] = {.0,.0,.05,.0,.0,.0,.0,.0,.0,.0}; TGraphErrors *gr1 = new TGraphErrors(n,x,y,ex,ey); gr1->SetFillStyle(3004); TGraphAsymmErrors *gr2 = new TGraphAsymmErrors(n, x, y, ex, ex, ey, ey); gr2->SetFillStyle(3005); TGraphBentErrors *gr3 = new TGraphBentErrors(n,x,y,ex,ex,ey,ey,exd,exd,eyd,eyd); gr3->SetFillStyle(3006); c1->DrawFrame(-1,0,1,10); gr1->Draw("2"); gr2->Draw("2"); gr3->Draw("2"); } - In PaintGraphBentErrors the fill style was not set for the boxes.
- The following macro displayed the histogram out of the frame
(option "b"):
{ gStyle->SetHistMinimumZero(); TH1F* h = new TH1F("h","h", 44, -0.5, 43.5); h->SetBarWidth(0.7); h->SetBarOffset(0.2); h->SetFillColor(kGreen); for (int i=0;i<44; i++ ) h->Fill(i, -i-60); h->DrawCopy("b"); } - It was not possible to interactively move a graph with many points close to each other. It was only possible to move the points one by one.
- PaintGrapHist: improvements with the option "][".
- The new markers (style 32 to 34) were not taken into account in the error bars drawing. Ie: the error bars were crossing the down triangle (style 32)
TGraph
- Fix a bug in TGraph::Eval when evaluating at the graph point values.
- With the following macro the axis title was not displayed:
{ TGraph *graph = new TGraph (); graph->SetPoint(0, 0.00100, 30.00); graph->SetPoint(1, 0.00150, 20.00); graph->SetPoint(2, 0.01150, 30.00); graph->Draw("AL*"); graph->GetXaxis()->SetTitle("foo") ; gPad->SetLogx(1) ; } - New method IsInside(x,y).
TMultiGraph
- New method IsInside(x,y).
THStack
- The color index used to erase the background while drawing a stack of 1D histogram was wrong.
TF1
- Bug fixed in TF1 zooming on Y axis. To reproduce it do:
root [0] TF1 f1( "f1", "-x", 1,3) root [1] f1.Draw()now selecting some range on the y-axis with the mouse jumped to the range (0, 1) instead of chosen range. - Add in TF1::GetX and TF1::GetMaximum, TF1::GetMinimum and TF1::GetMaximumX, TF1::GetMinimumX the tolerance and max number of iterations as extra parameters with default values of tolerance=10E-10 and max iterations=100
TH1
- Implement a faster version of TH1::FillRandom(TH1*,int) when the passed histogram has the same bins. In this case generate the flactuations bin by bins using Multinomial statistics
THnSparse
- Shrink THnSparse on disk by 70% in an arbitrary example case;
also reduce memory usage, especially when not filling.
IMPORTANT NOTE: while new THnSparse objects can be read and e.g. projected from in old ROOT versions, filling a new THnSparse object in old ROOT versions does NOT WORK! - Add SetBinContent(), AddBinContent(), SetBinError() taking the linear bin index. Use it in Projection() for a considerable speed-up.
TSpectrum2Painter
- New parameter bf() in the SPEC option to define the buffer size used by TSpectrum2Painter. It is needed in case of very large canvases like 8000x5000.
New TEfficiency class
- This new class from Christian Gumpert (CERN summer student 2010) handles the calculation of efficiencies and their uncertainties. It provides several statistical methods for calculating frequentist and bayesian confidence intervals as well as a function for combining several efficiencies.
- Example of usage: Creating a TEfficiency object
- If you start a new analysis, it is highly recommended to use the TEfficiency class from the beginning. You can then use one of the constructors for fixed or variable bin size and your desired dimension. These constructors append the created TEfficiency object to the current directory. So it will be written automatically to a file during the next TFile::Write command.
- Example 1: create a twodimensional TEfficiency object with 10
bins along X and 20 bins along Y:
TEfficiency* pEff = new TEfficiency("eff","my efficiency;x;y;#epsilon",10,0,10,20,-5,5); - You can fill the TEfficiency object by calling the Fill(Bool_t bPassed,Double_t x,Double_t y,Double_t z) method. The boolean flag "bPassed" indicates whether the current event is a good (both histograms are filled) or not (only fTotalHistogram is filled). The variables x,y and z determine the bin which is filled. For lower dimensions the z- or even the y-value may be omitted.
- You can also set the number of passed or total events for a bin directly by using the SetPassedEvents or SetTotalEvents method.
- If you already have two histograms filled with the number of passed and total events, you will use the constructor TEfficiency(const TH1& passed,const TH1& total) to construct the TEfficiency object. The histograms "passed" and "total" have to fullfill the conditions mentioned in CheckConsistency, otherwise the construction will fail.
- Example 2: Create TEfficiency from 2 existing histograms:
TEfficiency * pEff = 0; if (TEfficiency::CheckConsistency(h_pass,h_total)) pEff = new TEfficiency(h_pass,h_total);
- The TEfficiency class provides various statistics option based on frequentist or Bayesian statistics to compute the confidence interval on the efficiencies. For each statistical option a corresponding static function esists taking as parameters n, the number of total events, k, the number of passed events and cl the desired confidence level and a boolean flag specyfing if the upper (or lower) interval boundary must be computed. Each statistics option can be set using the method TEfficiency::SetStatisticOption
- The major statistics options are (see class
documentation for a full description and examples):
- Clopper_pearson (default) using the function TEfficiency::ClopperPearson(n, k, cl)
- Bayesian methods using the function TEfficiency::Bayesian(n, k, cl, alpha, beta). In this case the alpha and beta parameters of the beta prior distribution for the efficiency can be specified.
- Merging and combining different TEfficiency objects is supported (see the class documentation):
New TKDE class
- New class for Kernel density estimation from Bartolomeu Rabacal. The algorithm used is described in "Cranmer KS, Kernel Estimation in High-Energy Physics. Computer Physics Communications 136:198-207,2001" - e-Print Archive: hep ex/0011057 and more information can be found also in "Scott DW, Multivariate Density Estimation. Theory, Practice and Visualization. New York: Wiley", and "Jann Ben -, Univariate kernel density estimation document for KDENS ".
New TSVDUnfold class
TSVDUnfold implements the singular value decomposition based unfolding method proposed in NIM A372, 469 (1996) [hep-ph/9509307]. The regularisation is implemented as a discrete minimum curvature condition. This minimal implementation of TSVDUnfold provides unfolding of one-dimensional histograms with equal number of, not necessarily equidistant, bins in the measured and unfolded distributions. In addition to the unfolding itself, TSVDUnfold provides- Propagation of covariance matrices from the measured to the unfolded spectrum via GetUnfoldCovMatrix
- Evaluation of covariance matrix due to finite statistics in detector response via GetAdetCovMatrix
- Access to distribution of |d_i| useful for determining the proper regularisation via GetD
- Access to singular values via GetSV
New TH2Poly class
TH2Poly is a 2D Histogram class, inheriting from TH2, allowing to define polygonal bins of arbitary shape.Each bin, in a TH2Poly histogram, is a TH2PolyBin object. TH2PolyBin is a very simple class containing the vertices, stored as TGraphs and TMultiGraphs, and the content of the polygonal bin.
Bins are defined using one of the AddBin() methods. The bins definition should be done before filling.
TH2Poly implements a partitioning algorithm to speed up bins' filling. The following very simple macro shows how to build and fill a TH2Poly:
{
TH2Poly *h2p = new TH2Poly();
Double_t x1[] = {0, 5, 5};
Double_t y1[] = {0, 0, 5};
Double_t x2[] = {0, -1, -1, 0};
Double_t y2[] = {0, 0, -1, -1};
Double_t x3[] = {4, 3, 0, 1, 2.4};
Double_t y3[] = {4, 3.7, 1, 4.7, 3.5};
h2p->AddBin(3, x1, y1);
h2p->AddBin(3, x2, y2);
h2p->AddBin(3, x3, y3);
h2p->Fill( 3, 1, 3); // fill bin 1
h2p->Fill(-0.5, -0.5, 7); // fill bin 2
h2p->Fill(-0.7, -0.5, 1); // fill bin 2
h2p->Fill( 1, 3, 5); // fill bin 3
}
More examples can be found in $ROOTSYS/tutorials/hist/:
CINT
- Fix many reports from Coverity.
- Implement new selection #pragma for nested classes. #pragma link C++ nestedclasses is needed for CINT to not ignore #pragma link C++ class A::B. Unlike #pragma link C++ nestedtypedefs it does not by itself request dictionaries for nested classes! To not break old dictionaries, the latter is now implemented with the following syntax: #pragma link C++ class A::* will select all classes defined in A; CINT does not complain if no nested class is found. The selection pragma supports ROOT's flags (trailing '+' etc). This feature is now used by the automatic dictionary generator of ROOT, to not only request vector<T> but also vector<T>::iterator etc.
- Try in even more cases to automatically generate a dictionary for templates.
- Change the dictionary code generated for static const class data members
of integral type so that we access these data members only by value and
never attempt to take their address.
This allows us to work around bugs in the implementation of these kinds of data members in the Microsoft Visual C++ compilers (especially when dlls are involved it is difficult to get only one definition of the data member to be generated).
Because of these bugs a common pattern for windows programmers is to put the initialization in the header file and leave out the definition in the implementation file, which prevents the dictionary from taking the address of the data member (since it has none), so we change to use only the value, not the address.
Unfortunately the C++ standard explicitly allows these kind of data members to have no definition if they are not used in the program, see section 9.4.2 paragraph 4 of ISO/IEC 14882:1998(E).
In the case where a data member of this kind is not initialized in the header file and there is no definition in the source file, a link time error will be generated by the dictionary file.
Note that this is caused by the programmer forgetting to define the data member, but the error is usually hidden until code attempts to use it, which the dictionary must do.
- Add support for building with Microsoft Visual Studio 2010, including dictionaries for its new STL.
- Implement new prompt interface .preproc to toggle the external preprocessing of scripts. This does not work for any file #including e.g. TObject, as it disables ROOT's ignore-include mechanism for include files (see TROOT::IgnoreInclude()).
- Teach CINT's preprocessor to handle #TOKEN (i.e. string conversion of CPP tokens).
- Fix parsing of spacing (long long stays long long, no more Unknown type TH1Ghist instead of Unknown type TH1G.)
- Allow creation of dictionaries for auto_ptr.
- Mark explicitly that a member was brought into the class list of member via a using statement (Property G__BIT_ISUSINGVARIABLE). Use this information to avoid adding it to the Shadow classes.
- G__MethodInfo now properly distinguish between the 'creator/owner' of the G__MethodInfo object and the class in which the method is declared.
- Fix the registration and lookup of typedef to any nested types.
- Do not 'ignore' the semi-colons inside a string (passed as a argument to a .x command).
PyROOT
Python 3 is now in principle supported: a problem remains with passing builtin types by reference, since the internal object layout has changed. There may be further problems with handling of char*: all strings are unicode in p3, so if the C++ code is meant to see the char* as byte*, that won't work.
Other significant feature improvements include:
- Globally overloaded operators are now supported, and histogram unary multiplication with scalar is mapped onto TH1.Scale.
- Significant changes to equality and non-equality operators should make their behavior more consistent across the board, and in particular globally overloaded equality operators for STL iterators should work as expected (if a dictionary entry is generated for them).
- Global arrays of builtin types are now supported.
- Added further mappings of operator converters for builtin types.
- Individual methods can release the GIL, by setting the "_threaded" parameter of the method to True.
- Constructors need not be creators of new objects (controlled with their "_creates" parameters).
- Added access to TSelector protected data members in TPySelector.
- Derivable Fitter base classes are added for use with ROOT::Fitter.
- Special cases for RooFit are added to resolve a few specific overloading problems.
- A Python Warning is issued if a void* converter or executor is chosen out of necessity (e.g. because dictionaries are missing).
- A Python Warning is issued if keyword arguments are given (unsupported).
Notable bug fixes include:
- Object returns as a member of a temporary will keep a life line to that temporary, to prevent it from being destroyed in a long expression.
- Added "_" as a valid class name character.
- Speed of the destruction of memory-regulated objects has been improved (made linear, rather than quadratic).
Math Libraries
Mathcore
- New interface class ROOT::Math::DistSampler for
generating random number according to a given distribution.
- The class defines the methods to generate a single number DistSampler::Sample()or a data sets DistSampler::Generate(n, data). The data set generation can be unbinned or binned in the given range (only equidistant bins are currently supported)
- Sampling of 1D or multi-dim distributions is supported via the same interface
- Derived classes implementing this interface are not provided by MathCore but by other libraries and they can be instantiated using the plugin manager. Implementations based on Unuran and Foam exist.
- The tutorial math/multidimSampling.C is an example on how to use this class
- New class ROOT::Math::GoFTest for goodness of fit
tests of unbinned data
- The class implements the Kolmogorov-Smirnov and Anderson-Darling tests for two samples (data vs data ) and one sample (data vs distribution)
- For the data vs distribution test, the user can compare using a predefined distributions (Gaussian, LogNormal or Exponential) or by passing a user defined PDF or CDF.
- Example 1: perform a 2 sample GoF test from two arrays,
sample1[n1] and sample2[n2] containing the data
ROOT::Math::GoFTest goftest(n1, sample1, n2, sample2); double pValueAD = goftest.AndersonDarling2SamplesTest(); double pValueKS = goftest.KolmogorovSmirnov2SamplesTest();The class can return optionally also the test statistics instead of the p value. - Example 2: perform a 1 sample test with a pre-defined
distribution starting from a data set sample[n]
ROOT::Math::GoFTest goftest(n, sample, ROOT::Math::GoFTest::kGaussian); double pValueAD = goftest.AndersonDarlingTest(); double pValueKS = goftest.KolmogorovSmirnovTest(); - Example 3: perform a 1 sample test with a user-defined
distribution provided as cdf
ROOT::Math::Functor1D cdf_func(&ROOT::Math::landau_cdf); ROOT::Math::GofTest goftest(n, sample, cdf_func, ROOT::Math::GoFTest::kCDF); double pValueAD = goftest.AndersonDarlingTest(); - Example 4: perform a 1 sample test with a user-defined
distribution provided as pdf. Note that in this case to avoid
integration problems is sometimes recommended to give some
reasonable xmin and xmax values. xmin (and xmax) should however be
smaller (larger) than the minimum (maximum) data value.
ROOT::Math::Functor1D pdf_func(&ROOT::Math::landau_pdf); double xmin = 5*TMath::Min_Element(n,sample); double xmax = 5*TMath::Max_Element(n,sample); ROOT::Math::GofTest goftest(n, sample, pdf_func, ROOT::Math::GoFTest::kPDF,xmin,xmax); double pValueAD = goftest.AndersonDarlingTest(); - The tutorial math/goftest.C is an example on how to use the ROOT::Math::GofTest class
-
New class TKDTreeBinning for binning multidimensional data.
- The class implements multidimensional binning by constructing a TKDTree inner structure form the data which is used as the bins.
- The bins are retrieved as two double*, one for the minimum bin edges, the other as the maximum bin edges. For one dimension one of these is enough to correctly define the bins. The bin edges of d-dimensional data is a d-tet of the bin's thresholds. For example if d=3 the minimum bin edges of bin b is of the form of the following array: {xbmin, ybmin, zbmin}.
- Example 1: constructing a TKDTreeBinning object with
sample[dataSize] containing the data and dataDim and nBins,
multidimension and bin number parameters.
TKDTreeBinning* fBins = new TKDTreeBinning(dataSize, dataDim, sample, nBins); - Example 2: retrieving the bin edges. For the multidimensional case both minimum
and maximum ones are necessary for the bins to be well defined
Double_t* binsMinEdges = fBins->GetBinsMinEdges(); Double_t* binsMaxEdges = fBins->GetBinsMaxEdges();If you wish to retrieve them sorted by their density issue before the earlier getters fBins->SortBinsByDensity(); - Example 3: retrieving the bin edges of bin b. For the multidimensional
case both minimum and maximum ones are necessary for the bins to be well defined
std::pairbinEdges = fBins->GetBinEdges(b); - Example 4: perform queries on bin b information
Double_t density = GetBinDensity(b); Double_t volume = GetBinVolume(b); Double_t* center = GetBinCenter(b); - The tutorial math/kdTreeBinning.C is an example on how to use this class
- New statistical functions ROOT::Math::landau_quantile (inverse of landau cumulative distribution) translated from RANLAN and ROOT::Math::landau_quantile_c.
- New statistical functions ROOT::Math::negative_binomial_pdf and the cumulative distributions ROOT::Math::negative_binomial_cdf and ROOT::Math::negative_binomial_cdf_c.
- New special functions: sine and cosine integral, translated by B. List from CERNLIB: ROOT::Math::sinint and ROOT::Math::cosint
- New classes ROOT::Math::IOptions and ROOT::Math::GenAlgoOptions for dealing in general with the options for the numerical algorithm. The first one is the interface for the second and defines the setting and retrieval of generic pair of (name,value) options.
- They are used for defining possible extra options for the minimizer, integration and sampler options.
- Integration classes:
- Fix a bug in the templated method setting the integrand function
- Use now IntegrationOneDim::kADAPTIVESINGULAR as default method for the 1D integration
- Add the method IntegrationOneDim::kLEGENDRE based on the GaussLegendreIntegrator class.
- Implement also for the GaussIntegrator and GaussLegendreIntegrator the undefined and semi-undefined integral using a function transformation as it is done in the GSLIntegrator
- Fix a bug in IntegratorOneDim::SetAbsTolerance
- New class ROOT::Math::IntegratorOptions which can be passed to all integrator allowing the user to give options to the class and in particular default value. Via the support for extra options (with the class ROOT::Math::IOptions generic (string,value) options can be used in the base class to define specific options for the implementations. For example for the MCIntegrator class, specific options can now be passed to VEGAS or MISER.
- Improve the root finder and 1D minimization classes (BrentRootFinder and BrentMinimizer1D) by fixing a bug in the Brent method (see rev. 32544) and adding possibility to pass the tolerance and max number of iterations
- Change also the interface classes, ROOT::Math::RootFinder and ROOT::Math::IMinimizer1D to have methods consistent with the other numerical algorithm classes (e.g. return bool and not int from RootFinder::Solve and add a RootFinder::Status() function. In addition, use the same default tolerance for all the root finder algorithms.
- The class ROOT::Math::Data::Range returns in the method GetRange the values -inf and +inf when no range is set
- Use in TRandom::SetSeed(int seed) a value of seed=0 as default argument. This is the same now in all the derived classes.
- Add new methods in ROOT::Fit::FitResult to have a more consistent and expressive API:FitResult::Parameter(index), FitResult::ParError(index) and FitResult::ParName(index). The method FitResult::ParError should be used instead of FitResult::Error in the derived TFitResult class to avoid a conflict with TObject::Error (see bug 67671).
- Fix a bug in Tmath::AreEqualRel to take into account the case when the two arguments may be null.
- Improve implementation of the F distribution for large N and M. Use now the same implementation in ROOT::Math and TMath
- Fix the returned value of the incomplete gamma functions for a=0 or a is a negative integer number.
Mathmore
- Fix a bug in ROOT::Math::Random::Multinomial.
- Fix some bugs in GSLInterpolator
- New mathematical special functions in the ROOT::Math namespace
implemented using GSL:
- Airy functions:
double airy_Ai(double x); double airy_Bi(double x); double airy_Ai_deriv(double x); double airy_Bi_deriv(double x); double airy_zero_Ai(unsigned int s); double airy_zero_Bi(unsigned int s); double airy_zero_Ai_deriv(unsigned int s); double airy_zero_Bi_deriv(unsigned int s);
- Wigner coefficient functions:
double wigner_3j(int ja, int jb, int jc, int ma, int mb, int mc); double wigner_6j(int ja, int jb, int jc, int jd, int je, int jf); double wigner_9j(int ja, int jb, int jc, int jd, int je, int jf, int jg, int jh, int ji);
- Airy functions:
- New statistical function: non-central chisquare probability
density function
double noncentral_chisquared_pdf(double x, double r, double lambda);
It is implemented using Bessel functions or hypergeometric function - New classes VavilovAccurate and VavilovFast, derived from the abstract base class Vavilov, provide pdf, cdf and quantile functions for the Vavilov distribution, based on the algorithms of CERNLIB (G116 and G115, respectively). The classes VavilovAccuratePdf, VavilovAccurateCdf and VavilovAccurateQuantile implement the IParametricFunctionOneDim interface for easier use in fit problems.
Unuran
- Use new version 1.7.2
- Add new class TUnuranSampler implementing the ROOT::Math::DistSampler interface for one dimensional continuous and discrete distributions and for mult-dimensional ones
Foam
- Add new class TFoamSampler implementing the ROOT::Math::DistSampler interface for generating random numbers according to any one or multi-dim distributions using Foam.
- All the TFoam options can be controlled via the ROOT::Math::DistSamplerOptions class, which can be passed as input to the virtual ROOT::Math::DistSampler::Init(..) function.
GenVector
- Add some missing copy constructor and assignment operators to fix compilation issue observed with LLVM (Clang)
Minuit
- Fix a bug when using at the same time TMinuit or TFitter with the new TMinuitMinimizer class. See bug 72909.
Minuit2
- Fix the returned error from the Minimizer class for fixed and constant parameters. Now is set explicitly to zero.
- Fix a problem in re-defining fixed parameters as variable ones. Before it was not possible to release them.
- Fix a problem in the number of function calls when running MnHesse after minimizing. Now the number is incremented instead of being reset.
Genetic
- Add a new Minimizer implementation based on the genetic algorithm used in TMVA (plugin name "Genetic"). See example programs in math/genetic/test.
RooFit
- Assorted small bug fixes have been applied. No major new features have been introduced since 5.26
- Normalization of
- RooRealSumPdf changed from sum of coefficents to sum of coefficients*integrals of input functions.
- New PDF RooNonCentralChiSquare which is useful for asymptotic analysis of likelihood ratio tests -- like expected significance and error bands.
- Ability to "seal" data in RooNLLVar, so that an experiment can publish likleihood functions without exposing the data necessary to evaluate the likelihood function.
HistFactory
- The ROOT release ships with a script prepareHistFactory and a binary hist2workspace in the $ROOTSYS/bin directories.
- prepareHistFactory prepares a working area. It creates a results/, data/, and config/ directory. It also copies the HistFactorySchema.dtd and example XML files into the config/ directory. Additionally, it copies a root file into the data/ directory for use with the examples.
- Usage: hist2workspace input.xml
- HistFactorySchema.dtd: This file is located in $ROOTSYS/etc/ specifies the XML schema. It is typically placed in the config/ direc-tory of a working area together with the top-level XML file and the individual channel XML files. The user should not modify this file. The HistFactorySchema.dtd is commented to specify exactly the meaning of the various options.
Top-Level XML File
- see for example $ROOTSYS/tutorials/histfactory/example.xml
- This file is edited by the user. It specifies
- A top level 'Combination' that is composed of:
- several 'Channels', which are described in separate XML files.
- several 'Measurements' (corresponding to a full fit of the model) each of which specifies
- a name for this measurement to be used in tables and files
- what is the luminosity associated to the measurement in picobarns
- which bins of the histogram should be used
- what is the relative uncertainty on the luminosity
- what is (are) the parameter(s) of interest that will be measured
- which parameters should be fixed/floating (eg. nuisance parameters)
- which type of constriants are desired
- Gaussian by default
- Gamma, LogNormal, and Uniform are also supported
- if the tool should export the model only and skip the default fit
- A top level 'Combination' that is composed of:
Channel XML Files
- see for example $ROOTSYS/tutorials/histfactory/example_channel.xml
- This file is edited by the user. It specifies for each channel
- observed data (if absent the tool will use the expectation, which is useful for expected sensitivity)
- several 'Samples' (eg. signal, bkg1, bkg2, ...), each of which has:
- a name
- if the sample is normalized by theory (eg N = L*sigma) or not (eg. data driven)
- a nominal expectation histogram
- a named 'Normalization Factor' (which can be fixed or allowed to float in a fit)
- several 'Overall Systematics' in normalization with:
- a name
- +/- 1 sigma variations (eg. 1.05 and 0.95 for a 5% uncertainty)
- several 'Histogram Systematics' in shape with:
- a name (which can be shared with the OverallSyst if correlated)
- +/- 1 sigma variational histograms
RooStats
ModelConfig
- This class is now used extensively by the calculator tools. It encapsulates the configuration of a model to define a particular hypothesis.
- Various fixes by and improvements to make it usable with all the existing calculator.
- ModelConfig contains now always a reference to an external workspace who manages all the objects being part of the model (pdf's and parameter sets). The user needs then to set always a workspace pointer before setting the various objects.
General Improvements
- ModelConfig is now used extensively by the calculator tools. It encapsulates the configuration of a model to define a particular hypothesis.
- ProfileLikelihood::GetInterval now returns LikleihoodInterval in the interface to avoid unnecessary casting
- FeldmanCousins::GetInterval now returns PointSetInterval in the interface to avoid unnecessary casting
Profile Likelihood
- When running ProfileLikelihoodCalculator::GetHypoTest the user does not need anymore to clone the null parameter set. It is done now inside the calculator
- LikelihoodInterval::LowerLimit (and UpperLimit) returns now a boolean flag with the status of the limit search. In case of a failure in finding the upper/lower limit a value of zero is returned instead of the min/max of the variable range
- LikelihoodIntervalPlot fix drawing of horizontal green line when limits are outside the variable range
HybridCalculator
- New re-written class based on the TestStatSampler and TestStatistic interfaces. The new class is designed to provide consistent use of a ModelConfig, specifying the Pdf and Prior. The old class remains, but with a new name: HybridCalculatorOriginal.
- The tutorial rs201b_hybridcalculator shows the usage of the new class.
- Note that the new class can be constructed only from a ModelConfig
- One can specify a TestStatSampler in the constructor (which implies a choice of a TestStatistic, or by default the tool will use the ToyMCSampler and the RatioOfProfiledLikelihoods
- The interface of the new HybridCalculator class is now more uniform with the other calculator tools, which is different from the original HybridCalculator's interface. Users wishing to run their old macro are advised to use ModelConfig, but if that is too time consuming one can just change the name of the class from HybridCalculator to HybridCalculatorOriginal
- Note also that with the new class no HybridResult is returned but directly the base class HypoTestResult which has been improved for this release.
- The plot class, HybridPlot is not returned, but the user can create an HypoTestPlot object from the HypoTestResult.
- The classes HybridResult and HybridPlot work only with the HybridCalculatorOriginal and remain for maintaining a backward compatibility.
- Given a ModelConfig, the tool will attempt to form the posterior pdf for the nuisance parameters based on the prior and the constraint terms in the pdf. However, this is not yet implemented. In order to keep logical consistency with other tools, the distribution being used to smear the nuisance parameters should NOT be considered the prior in the model config. Instead, one should use HybridCalculator's ForcePriorNuisanceNull and ForcePriorNuisanceAlt.
HybridCalculatorOriginal
- Apply a fix for test statistic = 3 (profile likelihood)
- Apply a fix for using non-extended pdf
TestStatSampler and TestStatistics
- Cleanup of the interfaces.
- TestStatistics now have a method PValueIsRightTail to specify the sign conventions for the test statistic. This is used when making plots and calculating p-values.
- make clear that TestStatistic::Evaluate should take data and values of the parameters that defien the null.
- Add method TestStatSampler::SetParametersForTestStat that allows for greater control of parameters used for generating toy data and parameters used for evaluating the test statistic.
- ProfileLikelihoodTestStat Using the raw profile likelihood while reviewing the old algorithm used to provide robustness in situations with local minima.
- New test statistic classes:
- SimpleLikelihoodRatioTestStat : log L_1 / L_0
- RatioOfProfiledLikelihoodsTestStat: log L(mu_1, hat(nu_1))/L(mu_0,hat(nu_0))
- MaxLikelihoodEstiamteTestStat: the MLE of a specified parameter
ToyMCSampler
- New version of ToyMCSampler which can smear the nuisance parameters according to their distributions for use with HybridCalculator
- Updated class structure: ToyMCSampler is a particular implementation of a TestStatSampler and runs with any TestStatistic. It returns the result in an instance of SamplingDistribution.
- Supports Importance Sampling: Improves sampling the tails of a distribution by generating toys from a user supplied importance density and a reweighing procedure of the result.
- Supports Adaptive Sampling: extends the run until a given number of toys is reached in the tail(s).
- Parallelization using PROOF(-Lite) is supported. It is enabled by supplying a ProofConfig instance.
BayesianCalculator
- Improve the way the class performs the numerical integration to find the interval and/or the posterior function.
- In case of complex numerical calculation add the method SetScanOfPosterior(nbins) for scanning the posterior function in a givn number of nbins
- Add possibility to compute lower/upper limits using the method SetLeftSideTailFraction(fraction)
- Add possibility to compute shortest interval using SetShortestInterval
MCMCCalculator
- Various improvements including possibility to compute lower/central/upper limits using SetLeftSideTailFraction(fraction)
New Tutorials
- New Demos that take name for file, workspace, modelconfig, and data, then use the corresponding calculator tool. If the file is not specified it will read an file produced from running the HistFactory tutorial example.
- StandardProfileLikelihoodDemo.C:
- StandardFeldmanCousinsDemo.C:
- StandardBayesianMCMCDemo.C:
- StandardBayesianNumericalDemo.C:
- StandardProfileInspectorDemo.C:
- Demonstrate some new PDFs
- TestNonCentral.C: demonstrates non central chi-square
- JeffreysPriorDemo.C: demonstrates Jeffreys Prior
- Instructional Examples
- IntervalExamples.C: Standard Gaussian with known answer using 4 techniques
- FourBinInstructional.C: Example of a standard data-driven approach for estimating backgrounds. A lot of discussion.
- HybridInstructional.C: Example of protoype on/off problem with a data-driven background estimate. A lot of discussion
- HybridStandardForm.C: Variant on above in 'standard form'
- MultivariateGaussianTest.C: A validation example with an N-D multivariate Gaussian
TMVA
TMVA version 4.1.0 is included in this root release. The most important new feature is the support for simulataneous classification of multiple output classes for several multi-variate methods. A lot of effort went into consolidation of the software, i.e. method performance and robustness, and framework stability. The changes with respect to ROOT 5.27 / TMVA 4.0.7 are in detail:Framework
- Multi-class support. The support of multiple
output classes (i.e., more than a single background and signal
class) has been enabled for these methods: MLP (NN), BDTG,
FDA.
The multiclass functionality can be enabled with the Factory option"AnalysisType=multiclass". Training data is specified with an additional classname, e.g. viafactory->AddTree(tree,"classname");. After the training a genetic algorithm is invoked to determine the best cuts for selecting a specific class, based on the figure of merit: purity*efficiency. TMVA comes with two examples in$ROOTSYS/tmva/test:TMVAMulticlass.CandTMVAMulticlassApplication.C - New TMVA event vector building. The code for splitting the input data into training and test samples for all classes and the mixing of those samples to one training and one test sample has been rewritten completely. The new code is more performant and has a clearer structure. This fixes several bugs which have been reported by some users of TMVA.
- Code and performance test framework: A unit test framework for daily software and method performance validation has been implemented.
Methods
- BDT Automatic parameter optimisation for building the
tree architecture: The optimisation procedure uses the
performance of the trained classifier on the "test sample" for
finding the set of optimal parameters. Two different methods to
traverse the parameter space are available (scanning, genetic
algorithm). Currently parameter optimization is implemented only
for these three parameters that influence the tree architectur:
the maximum depth of a tree,
MaxDepth, the minimum number of events in each node,NodeMinEvents, and the number of tress,NTrees.Optimization can is invoked by callingAutomated and configurable parameter optimization is soon to be enabled for all methods (for those parameters where optimization is applicable).factory->OptimizeAllMethods();prior to the callfactory->TrainAllMethods();. - BDT node splitting: While Decision Trees typically have only univariate splits, in TMVA one can now also opt for multivariate splits that use a "Fisher Discriminant" (option: UseFisherCuts), built from all observables that show correlations larger than some threshold (MinLinCorrForFisher). The training will then test at each split a cut on this fisher discriminant in addition to all univariate cuts on the variables (or only on those variables that have not been used in the Fisher discriminant, option UseExcusiveVars). No obvious improvement betwen very simple decision trees after boosting has been observed so far, but only a limited number of studies has been performed concerning potiential benenfit of these simple multivariate splits.
Bug fixes
- A problem in the BDTG has been fixed, leading to a much improved regression performance.
- A problem in the TMVA::Reader has been fixed.
- With the new test framework and the coverity checks of ROOT a number of bugs were discovered and fixed. They mainly concerned memory leaks, and did not affect the performance.
Geometry
TGeoElement, TGeoIsotope
New class TGeoIsotope inside the file TGeoElement.h/.cxx. This is done for compatibility with GEANT4 isotopes and elements. TGeoElement class now contains the number of nucleons and an array of possible isotopes (as in GEANT4). One can make isotopes of the same element:
TGeoIsotope *iso1 = new TGeoIsotope("U235", Z,N1,A1);
TGeoIsotope *iso2 = new TGeoIsotope("U238", Z,N2,A2);
then an element containing the 2 isotopes:
TGeoElement *elem = new TGeoElement("U_nat", "U", 2); elem->AddIsotope(iso1,abundance1_percent); elem->AddIsotope(iso2,abundance2_percent);
Then one can make normal materials based on such elements. Added getters for isotopes from elements, as well as an isotope table within TGeoElementTable with search method by name (and not supporting several isotopes with the same name). Existing material table updated to use the number of nucleons. Everything backward compatible.
TGDMLParser
Several fixes and support for new features: Support for reading isotopes via the GDML parser. Interaction length now automatically computed using the algorithm from GEANT4. Fixed parsing of composite shapes. G4Ellipsoid is now supported in conversions.
MonteCarlo
TDatabasePDG
The method ReadPDGTable of TDatabasePDG was setting the stable flags for all particles regardless of their width.TParticlePDG
The value reported in the fLifetime variable of TParticlePDG is in seconds while in the documentation is was indicated in nanoseconds.pdg_table.txt
Particles with a width greater than 1e-10 have now the stable flag set to 1.TVirtualMC
New functions added in the interface:- For activation of collecting TGeo tracks:
virtual void SetCollectTracks(Bool_t collectTracks); virtual Bool_t IsCollectTracks() const;
- For accessing the normal vector of the crossing volume surface
on the geometry boundary:
virtual Bool_t CurrentBoundaryNormal(Double_t &x, Double_t &y, Double_t &z) const;
GUI
TGFileDialog
- Properly change directory when navigating in the directory tree.
- Make the File Dialog resizable.
TGFSContainer
- Create specific icons for symlinks (add a small arrow on the bottom left corner of the original icon).
TGListBox
- Enabled CurrentChanged(TGFrame*) and CurrentChanged(Int_t,Int_t) signals, allowing to handle keyboard navigation/selection.
For example:TGLBContainer *lbc = (TGLBContainer *)fListBox->GetContainer(); lbc->Connect("CurrentChanged(TGFrame*)", "MyGuiClass", this, "CurrentChanged(TGFrame*)"); void MyGuiClass::CurrentChanged(TGFrame *f) { TGTextLBEntry *lbe = (TGTextLBEntry *)f; printf("\nMyGuiClass::CurrentChanged() : Id = %d, Text = %s\n", lbe->EntryId(), lbe->GetTitle()); }
TGSlider
- Added SetEnabled(Bool_t) and SetState(Bool_t), allowing to disable or enable the TGSlider widgets (will be greyed if disabled).
TGToolTip
- Use a better way of positionning tooltips when they go out of screen
- Avoid to overlap the mouse pointer when repositioning it (flickering effect!)
TRootBrowser
- Implemented the alphabetical sorting mechanism in the file browser.
The sorting is applied only in the current directory and the browser remembers every sorted directory.
For this purpose, a new picture button has been added to the file browser plug-in (the status of this button reflects the sorting status of each directory)
Another button has been added to the file browser plug-in, used for refreshing the current directory in the list tree. Refreshing now checks also if files still exist in the current directory (for the case where files have been deleted by the user or by another application) - Allow to change graphic properties of an object (e.g. a histogram) in a Root file via the context menu from the browser (by opening a ged editor)
- Size of directories, trees, and objects associated to keys inside Root files, or any kind of browsable object can be displayed in their associated tooltip, as soon as their GetObjectInfo() method returns their size as a long long int formatted in a const char * ("%lld")
TRootContextMenu
- Close the context menu if the selected object is being deleted in the RecursiveRemove() operation.
TRootCanvas/TRootEmbeddedCanvas
- Drag and drop improvements for images (don't add margins between the canvas/pad border and the picture itself).
Graphical Output
PostScript and PDF
- The marker size between the screen output and the output file formats was not consistent.
- Implement the text kerning. The effect is clearly illustrated with
the following script. Without kerning the red X is overlaped by the
the rest of the text.
{ TCanvas *c = new TCanvas; TLatex *l = new TLatex(0.5, 0.5, "AVAVAVAVAVAVAVAVAVA#color[2]{X}"); l->Draw(); c->SaveAs("c1.eps"); }The original idea came from Oleksandr Grebenyuk. It has been implemented in a such way that the kerning mechanism is activated only when needed. If not needed the old way of text rendering is used. It was done that way because most of the time kerning is not needed and text rendered using the kerning mechanism takes more space in the PS/PDF files. - Very long text strings made wrong PS files.
- PDF also allows to define table of contents. Now, this facility can be used
in ROOT. The following example shows how to proceed:
{ TCanvas* canvas = new TCanvas("canvas"); TH1F* histo = new TH1F("histo","test 1",10,0.,10.); histo->SetFillColor(2); histo->Fill(2.); histo->Draw(); canvas->Print("plots.pdf(","Title:One bin filled"); histo->Fill(4.); histo->Draw(); canvas->Print("plots.pdf","Title:Two bins filled"); histo->Fill(6.); histo->Draw(); canvas->Print("plots.pdf","Title:Three bins filled"); histo->Fill(8.); histo->Draw(); canvas->Print("plots.pdf","Title:Four bins filled"); histo->Fill(8.); histo->Draw(); canvas->Print("plots.pdf)","Title:The fourth bin content is 2"); }Each character string following the keyword "Title:" makes a new entry in the table of contents. - TPostScript::Text: Inside a string, the backslash itself is now
escaped. The PS file generated by the two following lines did not work.
TText t(.5,.5,"\\t\\"); t.Draw(); - Small fix regarding line width in TPDF.
- In some cases there was some extra blanck page at the beginning of the PDF files. In particular when generated using the "[]" mechanism.
SVG
- The character #pm was not correct.
- Long polyline were not drawn correctly.
TASImage
- In the following macro the histogram drawing was done with wrong margins:
{ TImage *img = TImage::Open("$ROOTSYS/tutorials/image/rose512.jpg"); img->Draw("x"); gPad->Update(); TH1F *h1f = new TH1F("h1f","Test random numbers",100,-5,5); h1f->FillRandom("gaus",10000); h1f->Draw(); gPad->Update(); } - Improve the palette placement in TASImage::Paint (cf $ROOTSYS/tutorials/image/galaxy_image.C)
- GetWidth() and GetHeight() returned the size of the scaled image (if it exist) instead of the real size of the image.
- Initialize the Visual in TASImage::ReadImage. This fix a long standing problem with THtml: Without this fix all the embeded macros generating GUI output did not work in THtml.
TImageDump
Graphics Primitives
New text font: Symbol italic
- A new text font "Symbol Italic" has been implemented. It is working for all
possible outputs: screen, PS, PDF,SVG, gif etc ... It has the font number
15.
The following macro gives an example:{ TCanvas c("c","c",0,0,400,100); TLatex t0(.05,.45,"Symbol: #font[122]{abc} - Symbol Italic #font[152]{abc}"); t0.SetTextSize(0.36); t0.Draw(); c.Print("symbolitalic.ps"); c.Print("symbolitalic.pdf"); c.Print("symbolitalic.gif"); c.Print("symbolitalic.svg"); }
New markers
- Three new marker's styles are now available (32, 33, 34). They complement
the markers' list making sure each marker has a solid and an hollow
version.

TLatex
- The #int and #sum symbols had wrong limits placement
if the character just before started with "#". There was an atempt to fix
this problem in the previous release but it produced very bad side effects
therefore the fix was reverted. This new fix does not have this sidecw
effect. It causes, in the case of the "^" or "_" preceded by "sum" or
"int", to break off and process everything before "sum" or "int" first.
After that, when processing the rest, the "^" kicks in first according to
the order of precedence, and takes the "int" (only!) as its base.
Fix done by: Oleksandr Grebenyuk <ogrebenyuk@lbl.gov>. - Four new commands: #kern, #lower, #it and
#bf.
The two commands #kern and #lower enable a better control over characters placement. The command #kern[(Float_t)dx]{text} moves the output string horizontally by the fraction dx of its length. Similarly, #lower[(Float_t)dy]{text} shifts the text up or down by the fraction dy of its height.
Text can be turned italic or boldface using the commands #it and #bf.
Example:{ gStyle->SetTextFont(132); (new TLatex(0.01, 0.9, "Positive k#kern[0.3]{e}#kern[0.3]{r}#kern[0.3]{n}#kern[0.3]{i}#kern[0.3]{n}#kern[0.3]{g} with #^{}kern[0.3]"))->Draw(); (new TLatex(0.01, 0.7, "Negative k#kern[-0.3]{e}#kern[-0.3]{r}#kern[-0.3]{n}#kern[-0.3]{i}#kern[-0.3]{n}#kern[-0.3]{g} with #^{}kern[-0.3]"))->Draw(); (new TLatex(0.01, 0.5, "Vertical a#lower[0.2]{d}#lower[0.4]{j}#lower[0.1]{u}#lower[-0.1]{s}#lower[-0.3]{t}#lower[-0.4]{m}#lower[-0.2]{e}#lower[0.1]{n}t with #^{}lower[-0.4...+0.4]"))->Draw(); (new TLatex(0.01, 0.3, "Font styles: #^{}bf{#bf{bold}}, #^{}it{#it{italic}}, #^{}bf{#^{}it{#bf{#it{bold italic}}}}, #^{}bf{#^{}bf{#bf{#bf{unbold}}}}"))->Draw(); (new TLatex(0.01, 0.1, "Font styles: abc#alpha#beta#gamma, #^{}it{#it{abc#alpha#beta#gamma}}, #^{}it{#^{}it{#it{#it{abc#alpha#beta#gamma}}}}"))->Draw(); }
- Two new characters: #forall and #exists.
TText
- New method GetTextAdvance to return the text advance for string text taking the kerning into account or not.
TGaxis
- In case of horizontal axis with the font size in pixel (font precision = 3) the labels were not visible.
- Alpha numeric labels are not scaled anymore in case of text precision 3 (size in pixels). They are in the other precisions.
- Fix a precision issue on Mac. With the following lines the last label
(10^3) did not show:
t1 = new TH1F("test","test", 100,1,1000); t1.Draw(); gPad->SetLogx(1);
TPaveStats
- The stats painting assumed that the stats position was always defined with Y2>Y1 and X2>X1. This is true when the stats is created automatically but might not true if the stats position is given by user. This is now protected. The stats are correctly drawn whatever the orders of X and Y coordinates are.
- Saving canvas as a .C macro discarded white title and stat box background. Same thing with TPaveText.
TCutG
- IsInside(x,y) is now inherited from TGraph.
TCanvas and TPad
- In case of Canvas.MoveOpaque = true in $ROOTSYS/etc/system.rootrc the rubberband was not visible during the zooming along axis.
- TPad::SaveAs now takes care of the extensions .pdf], .pdf[, .pad( and .pdf) to avoid the PS and PDF mixing when a multiple pages PDF files is generated. To work around this problem it was enough to specify the option "pdf" in SaveAs.
- c->BuildLegend() created the legend in the current pad, not in c (as it should).
- A square TCanvas saved in batch mode in a ROOT file was not square anymore when displayed in interactive mode.
3D Graphics Primitives
TPolyMarker3D
- TPolyMarker3D::PaintH3 entered an infinite loop in case of huge bin content
OpenGL
Major changes
- GL in Pad: It is now possible to save a PadGL into a binary image file (gif, png, jpg etc...).
- Improve behaviour of TGLEventHandler and make it consistent:
- Process only one mouse button (the first pressed) at any time.
- All selections take effect on button release.
- Precsion modifiers Shift and Control can thus be pressed at any time for controlling rate of rotation, translation or zooming.
- Add support for multiple secondary-selection and partial
highlightning of secondary-selectable sub-items. This requires new
signals to be emitted from TGLViewer:
virtual void MouseOver (TObject *obj, UInt_t state); // *SIGNAL* virtual void ReMouseOver(TObject *obj, UInt_t state); // *SIGNAL* virtual void UnMouseOver(TObject *obj, UInt_t state); // *SIGNAL*
TGLEventHandler emits them when needed. For example see TEveDigitSet and its sub-classes TEveQuadSet and TEveBoxSet. - It is now possible to enforce all tesselations of geometry shapes to only use triangles via static function void TGLFaceSet::EnforceTriangles(). This is needed to export TGeo shapes and CSG meshes to external triangle-mesh libraries that can not handle arbitrary polygons.
- Add support for full-scene anti-aliasing (the actual benefits
depend on graphics card / driver). It is controlled via rootrc,
e.g.:
OpenGL.Framebuffer.Multisample: 4
Minor changes
- Extend configurability of GL event-handler to allow inversion of
controls from scene-centric to viewer-centric. The following rootrc
variables control the behaviour:
OpenGL.EventHandler.ViewerCentricControls: 1 OpenGL.EventHandler.ArrowKeyFactor: -1.0 OpenGL.EventHandler.MouseDragFactor: -1.0 OpenGL.EventHandler.MouseWheelFactor: -1.0
- Add camera auto-rotation support. Controls are available from the "Extras" tab of TGLViewer GUI editor. Implemented in class TGLAutoRotator, can be sub-classed and attached to a viewer via TGLViewer::SetAutoRotator() method.
- Added new overlay element class TGLCameraGuide that shows the
orientation of major axes. To use, call this on a TGLViewer object:
gl_viewer->AddOverlayElement(new TGLCameraGuide(0.9, 0.1, 0.08));
- Fix an issue with GL-clip object not being properly updated after a scene update.
- Hide / show menu-bar with a time-out (default 400ms). This can be
adjusted by calling static method:
TGLSAViewer::SetMenuHidingTimeout(200);
To disable menu hiding for Eve viewers, where it is enabled by default, set the following rootrc variable:Eve.Viewer.HideMenus: off
EVE
Major changes
- Implement central infractructure to allow eve-elements to support
internal multiple selection and highlightning of their sub-parts.
Use this in TEveDigitSet and its sub-classes TEveQuadSet and TEveBoxSet.- TEveSecondarySelectable: New secondary base-class for elements supporting internal multiple selection / highlight.
- TEveViewer - Add functions to handle additional mouse-over signals from TGLViewer.
- TEveElement - Add 3 new functions:
virtual TString GetHighlightTooltip(); virtual void UnSelected(); virtual void UnHighlighted(); - TEveDigitSet, TEveQuadSet, TEveBoxSet
- Sub-class TEveDigitSet from TEveSecondarySelectable.
- Implement functions needed for internal selection.
- Add common base-class TEveDigitSetGL for quad and box-set GL rendering.
- Move anti-flickering controls from TEveQuadSet to TEveDigitSet and implement it also in TEveBoxSetGL.
- TEveChunkManager: Add support for restricted iteration. TEveChunkManager::iterator accepts set<Int_t> for that purpose.
- TEveElement: Extensions for configurable selection / highlight /
color / transparency propagation between compounds and elements. The
following options can be activated:
- ImplySelectAllChildren() - to highlight / imply-select all children of an compound;
- TakeAnyParentAsMaster() - to upwards propagate mouse-selection to any compound parent;
- ApplyMainColorToAllChildren() / ApplyMainColorToMatchingChildren() to request color propagation to all / matching children of a compound;
- ApplyMainTransparencyToAllChildren() / ApplyMainTransparencyToMatchingChildren() to request transparency propagation to all / matching children of a compound.
- TEveElement: propagate transparency to projected replicas. As this is implemented in the base-class, it works for all projectable classes.
-
TEveVector, TEveVector4 and TEveVector2 are now typedefs to float
specialization of corresponding templates. Double versions use 'D' as
postfix, 'F' postfix is another alias for float versions, e.g.:
typedef TEveVectorT<Float_t> TEveVector; typedef TEveVectorT<Float_t> TEveVectorF; typedef TEveVectorT<Double_t> TEveVectorD; - All projectable classes now take into account their transformation matrix. The projected versions are still stored in global coordinates.
- TEveShape -- a new abstract base-class for 2D/3D shapes that require fill / outline color, line-width and various flags controlling the area / outline drawing.
- TEveGeoShape and projected classes: subclass from TEveShape. Add support for TGeoCompositeShapes. In 2D projected class (TEvePolygonSetProjected) improve detection of duplicate polygons and add support for detection of minimal-outline (triggered via Bool_t TEveShape::fMiniOutline).
- TEveBox: New class to draw a simple cuboid with minimal memory usage. It is projectable.
- TEveBoxSet: for box-type kBT_FreeBox assure proper face orientation at registration time and calculate normals when rendering.
- TEveJetCone is now projectable.
- Several performance improvements when dealing with large collections of EVE objects. Profiled with simulated heavy-ion data. In particular, for destruction of self-contained sub-hierarchies of objects one can use TEveElement::Annihilate() and TEveElement::AnnihilateElements(). See class docs for constraints.
Minor changes
- Add support for projecting a new child (all children) of an
element after the element and its old children have already been
projected. This is provided by the following virtual functions in
TEveElement:
void ProjectChild(TEveElement* el, Bool_t sameDepth=kTRUE); void ProjectAllChildren(Bool_t same_depth=kTRUE);
- Several improvements in drawing of TEveCalo axes and labels.
- TEveTrackPropagator. Fix some issues with Runge-Kutta track propagator. Move in controls specifying how to plot tracks that get split in RhoZ projection.
- Fix rendering of TEveJetCone: normals at apex were not changing as they should.
- Support single-color for TEveDigitSet (call TEveDigitSet::UseSingleColor()).
- Always add children of an element to the GUI list-tree. There was a problem when elements having children were added to the list-tree, the children were not added.
- TEveLine has its own icon now. The icon for TEvePointSet was used before and this caused confusion.
Misc
Tutorials
- New tutorial $ROOTSYS/tutorials/graphics/mass_spectrum.C. It
produces the following output:
- New tutorial $ROOTSYS/math/goftest.C showing the example usage of the new ROOT::Math::GoFTest class.
- New tutorial $ROOTSYS/math/multiDimSampling.C showing the example usage of the new ROOT::Math::DistSampler interface for random generation from arbitrary functions using Unuran or Foam.
- New tutorial $ROOTSYS/math/kdTreeBinning.C showing the example usage of the new TKDTreeBinning class.
- New tutorial $ROOTSYS/fit/NumericalMinimization.C showing a minimization example (Rosenbrock function) using the ROOT::Math::Minimizer interface.
- New tutorial $ROOTSYS/fit/exampleFit3D.C showing a simple fit example of 3D points with a 3D function.
- New tutorial $ROOTSYS/fit/TSVDUnfoldExample.C showing an example of the new TSVDUnfold class.
- New Roostats tutorials:
- New Demos that take name for file, workspace, modelconfig, and data, then use the corresponding calculator tool. If the file is not specified it will read an file produced from running the HistFactory tutorial example.
- StandardProfileLikelihoodDemo.C:
- StandardFeldmanCousinsDemo.C:
- StandardBayesianMCMCDemo.C:
- StandardBayesianNumericalDemo.C:
- StandardProfileInspectorDemo.C:
- Demonstrate some new PDFs
- TestNonCentral.C: demonstrates non central chi-square
- JeffreysPriorDemo.C: demonstrates Jeffreys Prior
- Instructional Examples
- IntervalExamples.C: Standard Gaussian with known answer using 4 techniques
- FourBinInstructional.C: Example of a standard data-driven approach for estimating backgrounds. A lot of discussion.
- HybridInstructional.C: Example of protoype on/off problem with a data-driven background estimate. A lot of discussion
- HybridStandardForm.C: Variant on above in 'standard form'
- MultivariateGaussianTest.C: A validation example with an N-D multivariate Gaussian
- Renamed the rs201_hybridcalculator.C to HybridOriginalDemo.C
- Removed some obsolete roostats tutorials (all the rs500 types)
- New Demos that take name for file, workspace, modelconfig, and data, then use the corresponding calculator tool. If the file is not specified it will read an file produced from running the HistFactory tutorial example.