| library: libSPlot #include "TSPlot.h" |
| Inheritance Chart: | |||||||||
|
protected:
void SPlots(Double_t* covmat, Int_t i_excl)
public:
TSPlot()
TSPlot(Int_t nx, Int_t ny, Int_t ne, Int_t ns, TTree* tree)
virtual ~TSPlot()
virtual void Browse(TBrowser* b)
static TClass* Class()
void FillSWeightsHists(Int_t nbins = 50)
void FillXvarHists(Int_t nbins = 100)
void FillYpdfHists(Int_t nbins = 100)
void FillYvarHists(Int_t nbins = 100)
Int_t GetNevents()
Int_t GetNspecies()
void GetSWeights(TMatrixD& weights)
void GetSWeights(Double_t* weights)
TH1D* GetSWeightsHist(Int_t ixvar, Int_t ispecies, Int_t iyexcl = -1)
TObjArray* GetSWeightsHists()
TString* GetTreeExpression()
TString* GetTreeName()
TString* GetTreeSelection()
TH1D* GetXvarHist(Int_t ixvar)
TObjArray* GetXvarHists()
TH1D* GetYpdfHist(Int_t iyvar, Int_t ispecies)
TObjArray* GetYpdfHists()
TH1D* GetYvarHist(Int_t iyvar)
TObjArray* GetYvarHists()
virtual TClass* IsA() const
virtual Bool_t IsFolder() const
void MakeSPlot(Option_t* option = "v")
void RefillHist(Int_t type, Int_t var, Int_t nbins, Double_t min, Double_t max, Int_t nspecies = -1)
void SetInitialNumbersOfSpecies(Int_t* numbers)
void SetNEvents(Int_t ne)
void SetNSpecies(Int_t ns)
void SetNX(Int_t nx)
void SetNY(Int_t ny)
void SetTree(TTree* tree)
void SetTreeSelection(const char* varexp = "", const char* selection = "", Long64_t firstentry = 0)
virtual void ShowMembers(TMemberInspector& insp, char* parent)
virtual void Streamer(TBuffer& b)
void StreamerNVirtual(TBuffer& b)
protected:
TMatrixD fXvar !
TMatrixD fYvar !
TMatrixD fYpdf !
TMatrixD fPdfTot !
TMatrixD fMinmax mins and maxs of variables for histogramming
TMatrixD fSWeights computed sWeights
TObjArray fXvarHists histograms of control variables
TObjArray fYvarHists histograms of discriminating variables
TObjArray fYpdfHists histograms of pdfs
TObjArray fSWeightsHists histograms of weighted variables
TTree* fTree !
TString* fTreename The name of the data tree
TString* fVarexp Variables used for splot
TString* fSelection Selection on the tree
Int_t fNx Number of control variables
Int_t fNy Number of discriminating variables
Int_t fNSpecies Number of species
Int_t fNevents Total number of events
Double_t* fNumbersOfEvents [fNSpecies] estimates of numbers of events in each species
Overview
A common method used in High Energy Physics to perform measurements is the maximum Likelihood method, exploiting discriminating variables to disentangle signal from background. The crucial point for such an analysis to be reliable is to use an exhaustive list of sources of events combined with an accurate description of all the Probability Density Functions (PDF).
To assess the validity of the fit, a convincing quality check is to explore further the data sample by examining the distributions of control variables. A control variable can be obtained for instance by removing one of the discriminating variables before performing again the maximum Likelihood fit: this removed variable is a control variable. The expected distribution of this control variable, for signal, is to be compared to the one extracted, for signal, from the data sample. In order to be able to do so, one must be able to unfold from the distribution of the whole data sample.
The TSPlot method allows to reconstruct the distributions for the control variable, independently for each of the various sources of events, without making use of any a priori knowledge on this variable. The aim is thus to use the knowledge available for the discriminating variables to infer the behaviour of the individual sources of events with respect to the control variable.
TSPlot is optimal if the control variable is uncorrelated with the discriminating variables.
A detail description of the formalism itself, called
![]() , is given in [1].
, is given in [1].
The method
The
![]() technique is developped in the above context of a maximum Likelihood method making use of discriminating variables.
technique is developped in the above context of a maximum Likelihood method making use of discriminating variables.
One considers a data sample in which are merged several species of events. These species represent various signal components and background components which all together account for the data sample. The different terms of the log-Likelihood are:
The class TSPlot allows to reconstruct the true distribution
![]() of a control variable
of a control variable ![]() for each of the
for each of the
![]() species from the sole knowledge of the PDFs of the discriminating variables
species from the sole knowledge of the PDFs of the discriminating variables ![]() . The plots obtained thanks to the TSPlot class are called
. The plots obtained thanks to the TSPlot class are called
![]() .
.
Some properties and checks
Beside reproducing the true distribution,
![]() bear remarkable properties:
bear remarkable properties:
Different steps followed by TSPlot
Illustrations
To illustrate the technique, one considers an example derived from the analysis where
![]() have been first used (charmless B decays). One is dealing with a data
sample in which two species are present: the first is termed signal and
the second background. A maximum Likelihood fit is performed to obtain
the two yields
have been first used (charmless B decays). One is dealing with a data
sample in which two species are present: the first is termed signal and
the second background. A maximum Likelihood fit is performed to obtain
the two yields ![]() and
and ![]() . The fit relies on two discriminating variables collectively denoted
. The fit relies on two discriminating variables collectively denoted ![]() which are chosen within three possible variables denoted
which are chosen within three possible variables denoted ![]() ,
, ![]() and
and ![]() .
The variable which is not incorporated in
.
The variable which is not incorporated in ![]() is used as the control variable
is used as the control variable ![]() . The six distributions of the three variables are assumed to be the ones depicted in Fig. 1.
. The six distributions of the three variables are assumed to be the ones depicted in Fig. 1.
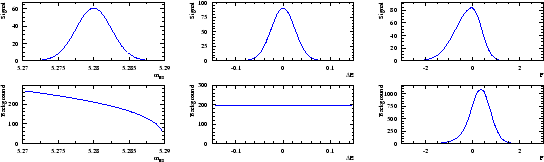 |
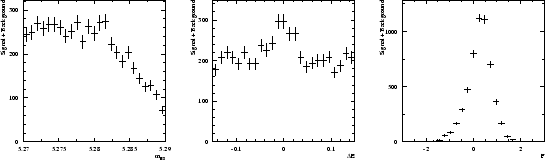
A data sample being built through a Monte Carlo simulation based on the distributions shown in Fig. 1, one obtains the three distributions of Fig. 2. Whereas the distribution of ![]() clearly indicates the presence of the signal, the distribution of
clearly indicates the presence of the signal, the distribution of ![]() and
and ![]() are less obviously populated by signal.
are less obviously populated by signal.
 |
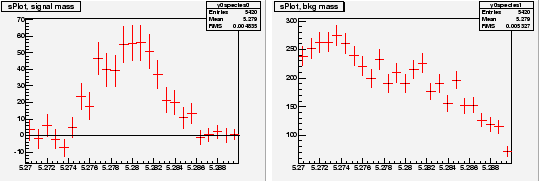
Chosing ![]() and
and ![]() as discriminating variables to determine
as discriminating variables to determine ![]() and
and ![]() through a maximum Likelihood fit, one builds, for the control variable
through a maximum Likelihood fit, one builds, for the control variable ![]() which is unknown to the fit, the two
which is unknown to the fit, the two
![]() for signal and background shown in Fig. 3. One observes that the
for signal and background shown in Fig. 3. One observes that the
![]() for signal reproduces correctly the PDF even where the latter vanishes,
although the error bars remain sizeable. This results from the almost
complete cancellation between positive and negative weights: the sum of
weights is close to zero while the sum of weights squared is not. The
occurence of negative weights occurs through the appearance of the
covariance matrix, and its negative components, in the definition of
Eq. (2).
for signal reproduces correctly the PDF even where the latter vanishes,
although the error bars remain sizeable. This results from the almost
complete cancellation between positive and negative weights: the sum of
weights is close to zero while the sum of weights squared is not. The
occurence of negative weights occurs through the appearance of the
covariance matrix, and its negative components, in the definition of
Eq. (2).
A word of caution is in order with respect to the error bars. Whereas
their sum in quadrature is identical to the statistical uncertainties
of the yields determined by the fit, and if, in addition, they are
asymptotically correct, the error bars should be handled with care for
low statistics and/or for too fine binning. This is because the error
bars do not incorporate two known properties of the PDFs: PDFs are
positive definite and can be non-zero in a given x-bin, even if in the
particular data sample at hand, no event is observed in this bin. The
latter limitation is not specific to
![]() ,
rather it is always present when one is willing to infer the PDF at the
origin of an histogram, when, for some bins, the number of entries does
not guaranty the applicability of the Gaussian regime. In such
situations, a satisfactory practice is to attach allowed ranges to the
histogram to indicate the upper and lower limits of the PDF value which
are consistent with the actual observation, at a given confidence
level.
,
rather it is always present when one is willing to infer the PDF at the
origin of an histogram, when, for some bins, the number of entries does
not guaranty the applicability of the Gaussian regime. In such
situations, a satisfactory practice is to attach allowed ranges to the
histogram to indicate the upper and lower limits of the PDF value which
are consistent with the actual observation, at a given confidence
level.
 |
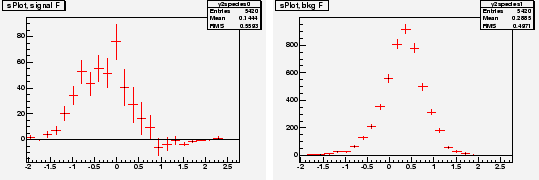
Chosing ![]() and
and ![]() as discriminating variables to determine
as discriminating variables to determine ![]() and
and ![]() through a maximum Likelihood fit, one builds, for the control variable
through a maximum Likelihood fit, one builds, for the control variable ![]() which is unknown to the fit, the two
which is unknown to the fit, the two
![]() for signal and background shown in Fig. 4. In the
for signal and background shown in Fig. 4. In the
![]() for signal one observes that error bars are the largest in the
for signal one observes that error bars are the largest in the ![]() regions where the background is the largest.
regions where the background is the largest.
 |
The results above can be obtained by running the tutorial TestSPlot.C
default constructor (used by I/O only)
normal TSPlot constructor nx : number of control variables ny : number of discriminating variables ne : total number of events ns : number of species tree: input data
destructor
To browse the histograms
Set the initial number of events of each species - used as initial estimates in minuit
Calculates the sWeights The option controls the print level "Q" - no print out "V" - prints the estimated #of events in species - default "VV" - as "V" + the minuit printing + sums of weights for control
Computes the sWeights from the covariance matrix
Returns the matrix of sweights
Returns the matrix of sweights. It is assumed that the array passed in the argurment is big enough
Fills the histograms of x variables (not weighted) with nbins
Returns the array of histograms of x variables (not weighted) If histograms have not already been filled, they are filled with default binning 100.
Returns the histogram of variable #ixvar If histograms have not already been filled, they are filled with default binning 100.
Fill the histograms of y variables
Returns the array of histograms of y variables. If histograms have not already been filled, they are filled with default binning 100.
Returns the histogram of variable iyvar.If histograms have not already been filled, they are filled with default binning 100.
Fills the histograms of pdf-s of y variables with binning nbins
Returns the array of histograms of pdf's of y variables with binning nbins If histograms have not already been filled, they are filled with default binning 100.
Returns the histogram of the pdf of variable #iyvar for species #ispecies, binning nbins If histograms have not already been filled, they are filled with default binning 100.
The order of histograms in the array: x0_species0, x0_species1,..., x1_species0, x1_species1,..., y0_species0, y0_species1,... If the histograms have already been filled with a different binning, they are refilled and all histograms are deleted
Returns an array of all histograms of variables, weighted with sWeights If histograms have not been already filled, they are filled with default binning 50 The order of histograms in the array: x0_species0, x0_species1,..., x1_species0, x1_species1,..., y0_species0, y0_species1,...
The Fill...Hist() methods fill the histograms with the real limits on the variables
This method allows to refill the specified histogram with user-set boundaries min and max
Parameters:
type = 1 - histogram of x variable #nvar
= 2 - histogram of y variable #nvar
= 3 - histogram of y_pdf for y #nvar and species #nspecies
= 4 - histogram of x variable #nvar, species #nspecies, WITH sWeights
= 5 - histogram of y variable #nvar, species #nspecies, WITH sWeights
Returns the histogram of a variable, weithed with sWeights If histograms have not been already filled, they are filled with default binning 50 If parameter ixvar!=-1, the histogram of x-variable #ixvar is returned for species ispecies If parameter ixvar==-1, the histogram of y-variable #iyexcl is returned for species ispecies If the histogram has already been filled and the binning is different from the parameter nbins all histograms with old binning will be deleted and refilled.
Set the input Tree
Specifies the variables from the tree to be used for splot Variables fNx, fNy, fNSpecies and fNEvents should already be set! In the 1st parameter it is assumed that first fNx variables are x(control variables), then fNy y variables (discriminating variables), then fNy*fNSpecies ypdf variables (probability distribution functions of dicriminating variables for different species). The order of pdfs should be: species0_y0, species0_y1,... species1_y0, species1_y1,...species[fNSpecies-1]_y0... The 2nd parameter allows to make a cut TTree::Draw method description contains more details on specifying expression and selection
Bool_t IsFolder() const
Int_t GetNevents()
Int_t GetNspecies()
TString* GetTreeName()
TString* GetTreeSelection()
TString* GetTreeExpression()
void SetNX(Int_t nx)
void SetNY(Int_t ny)
void SetNSpecies(Int_t ns)
void SetNEvents(Int_t ne)
TClass* Class()
TClass* IsA() const
void ShowMembers(TMemberInspector& insp, char* parent)
void Streamer(TBuffer& b)
void StreamerNVirtual(TBuffer& b)
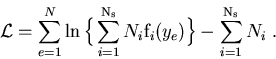
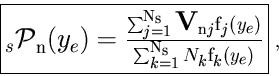
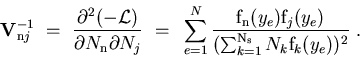
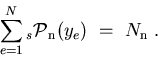
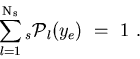
![\begin{displaymath}
\sigma[N_{\rm n}\ _s\tilde{\rm M}_{\rm n}(x) {\delta x}]~=~\sqrt{\sum_{e \subset {\delta x}} ({_s{\cal P}}_{\rm n})^2} ~.
\end{displaymath}](gif/sPlot_img26.png)