******************************************************************************
*Tree :sig_tree : tree *
*Entries : 10000 : Total = 1177229 bytes File Size = 785298 *
* : : Tree compression factor = 1.48 *
******************************************************************************
*Br 0 :Type : Type/F *
*Entries : 10000 : Total Size= 40556 bytes File Size = 307 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 130.54 *
*............................................................................*
*Br 1 :lepton_pT : lepton_pT/F *
*Entries : 10000 : Total Size= 40581 bytes File Size = 30464 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.32 *
*............................................................................*
*Br 2 :lepton_eta : lepton_eta/F *
*Entries : 10000 : Total Size= 40586 bytes File Size = 28650 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.40 *
*............................................................................*
*Br 3 :lepton_phi : lepton_phi/F *
*Entries : 10000 : Total Size= 40586 bytes File Size = 30508 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.31 *
*............................................................................*
*Br 4 :missing_energy_magnitude : missing_energy_magnitude/F *
*Entries : 10000 : Total Size= 40656 bytes File Size = 35749 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.12 *
*............................................................................*
*Br 5 :missing_energy_phi : missing_energy_phi/F *
*Entries : 10000 : Total Size= 40626 bytes File Size = 36766 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.09 *
*............................................................................*
*Br 6 :jet1_pt : jet1_pt/F *
*Entries : 10000 : Total Size= 40571 bytes File Size = 32298 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.24 *
*............................................................................*
*Br 7 :jet1_eta : jet1_eta/F *
*Entries : 10000 : Total Size= 40576 bytes File Size = 28467 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.41 *
*............................................................................*
*Br 8 :jet1_phi : jet1_phi/F *
*Entries : 10000 : Total Size= 40576 bytes File Size = 30399 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.32 *
*............................................................................*
*Br 9 :jet1_b-tag : jet1_b-tag/F *
*Entries : 10000 : Total Size= 40586 bytes File Size = 5087 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 7.88 *
*............................................................................*
*Br 10 :jet2_pt : jet2_pt/F *
*Entries : 10000 : Total Size= 40571 bytes File Size = 31561 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.27 *
*............................................................................*
*Br 11 :jet2_eta : jet2_eta/F *
*Entries : 10000 : Total Size= 40576 bytes File Size = 28616 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.40 *
*............................................................................*
*Br 12 :jet2_phi : jet2_phi/F *
*Entries : 10000 : Total Size= 40576 bytes File Size = 30547 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.31 *
*............................................................................*
*Br 13 :jet2_b-tag : jet2_b-tag/F *
*Entries : 10000 : Total Size= 40586 bytes File Size = 5031 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 7.97 *
*............................................................................*
*Br 14 :jet3_pt : jet3_pt/F *
*Entries : 10000 : Total Size= 40571 bytes File Size = 30642 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.31 *
*............................................................................*
*Br 15 :jet3_eta : jet3_eta/F *
*Entries : 10000 : Total Size= 40576 bytes File Size = 28955 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.38 *
*............................................................................*
*Br 16 :jet3_phi : jet3_phi/F *
*Entries : 10000 : Total Size= 40576 bytes File Size = 30433 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.32 *
*............................................................................*
*Br 17 :jet3_b-tag : jet3_b-tag/F *
*Entries : 10000 : Total Size= 40586 bytes File Size = 4879 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 8.22 *
*............................................................................*
*Br 18 :jet4_pt : jet4_pt/F *
*Entries : 10000 : Total Size= 40571 bytes File Size = 29189 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.37 *
*............................................................................*
*Br 19 :jet4_eta : jet4_eta/F *
*Entries : 10000 : Total Size= 40576 bytes File Size = 29311 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.37 *
*............................................................................*
*Br 20 :jet4_phi : jet4_phi/F *
*Entries : 10000 : Total Size= 40576 bytes File Size = 30525 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.31 *
*............................................................................*
*Br 21 :jet4_b-tag : jet4_b-tag/F *
*Entries : 10000 : Total Size= 40586 bytes File Size = 4725 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 8.48 *
*............................................................................*
*Br 22 :m_jj : m_jj/F *
*Entries : 10000 : Total Size= 40556 bytes File Size = 34991 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.15 *
*............................................................................*
*Br 23 :m_jjj : m_jjj/F *
*Entries : 10000 : Total Size= 40561 bytes File Size = 34460 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.16 *
*............................................................................*
*Br 24 :m_lv : m_lv/F *
*Entries : 10000 : Total Size= 40556 bytes File Size = 32232 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.24 *
*............................................................................*
*Br 25 :m_jlv : m_jlv/F *
*Entries : 10000 : Total Size= 40561 bytes File Size = 34598 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.16 *
*............................................................................*
*Br 26 :m_bb : m_bb/F *
*Entries : 10000 : Total Size= 40556 bytes File Size = 35012 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.14 *
*............................................................................*
*Br 27 :m_wbb : m_wbb/F *
*Entries : 10000 : Total Size= 40561 bytes File Size = 34493 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.16 *
*............................................................................*
*Br 28 :m_wwbb : m_wwbb/F *
*Entries : 10000 : Total Size= 40566 bytes File Size = 34410 *
*Baskets : 1 : Basket Size= 1500672 bytes Compression= 1.16 *
*............................................................................*
DataSetInfo : [dataset] : Added class "Signal"
: Add Tree sig_tree of type Signal with 10000 events
DataSetInfo : [dataset] : Added class "Background"
: Add Tree bkg_tree of type Background with 10000 events
Factory : Booking method: ␛[1mLikelihood␛[0m
:
Factory : Booking method: ␛[1mFisher␛[0m
:
Factory : Booking method: ␛[1mBDT␛[0m
:
: Rebuilding Dataset dataset
: Building event vectors for type 2 Signal
: Dataset[dataset] : create input formulas for tree sig_tree
: Building event vectors for type 2 Background
: Dataset[dataset] : create input formulas for tree bkg_tree
DataSetFactory : [dataset] : Number of events in input trees
:
:
: Number of training and testing events
: ---------------------------------------------------------------------------
: Signal -- training events : 7000
: Signal -- testing events : 3000
: Signal -- training and testing events: 10000
: Background -- training events : 7000
: Background -- testing events : 3000
: Background -- training and testing events: 10000
:
DataSetInfo : Correlation matrix (Signal):
: ----------------------------------------------------------------
: m_jj m_jjj m_lv m_jlv m_bb m_wbb m_wwbb
: m_jj: +1.000 +0.777 +0.010 +0.107 +0.036 +0.517 +0.532
: m_jjj: +0.777 +1.000 +0.006 +0.083 +0.157 +0.682 +0.669
: m_lv: +0.010 +0.006 +1.000 +0.111 -0.026 +0.011 +0.023
: m_jlv: +0.107 +0.083 +0.111 +1.000 +0.325 +0.550 +0.555
: m_bb: +0.036 +0.157 -0.026 +0.325 +1.000 +0.463 +0.347
: m_wbb: +0.517 +0.682 +0.011 +0.550 +0.463 +1.000 +0.912
: m_wwbb: +0.532 +0.669 +0.023 +0.555 +0.347 +0.912 +1.000
: ----------------------------------------------------------------
DataSetInfo : Correlation matrix (Background):
: ----------------------------------------------------------------
: m_jj m_jjj m_lv m_jlv m_bb m_wbb m_wwbb
: m_jj: +1.000 +0.804 +0.017 +0.125 +0.007 +0.381 +0.394
: m_jjj: +0.804 +1.000 +0.025 +0.159 +0.153 +0.535 +0.520
: m_lv: +0.017 +0.025 +1.000 +0.114 +0.042 +0.064 +0.069
: m_jlv: +0.125 +0.159 +0.114 +1.000 +0.286 +0.592 +0.542
: m_bb: +0.007 +0.153 +0.042 +0.286 +1.000 +0.623 +0.441
: m_wbb: +0.381 +0.535 +0.064 +0.592 +0.623 +1.000 +0.878
: m_wwbb: +0.394 +0.520 +0.069 +0.542 +0.441 +0.878 +1.000
: ----------------------------------------------------------------
DataSetFactory : [dataset] :
:
Factory : Booking method: ␛[1mDNN_CPU␛[0m
:
: Parsing option string:
: ... "!H:V:ErrorStrategy=CROSSENTROPY:VarTransform=G:WeightInitialization=XAVIER:InputLayout=1|1|7:BatchLayout=1|128|7:Layout=DENSE|64|TANH,DENSE|64|TANH,DENSE|64|TANH,DENSE|64|TANH,DENSE|1|LINEAR:TrainingStrategy=LearningRate=1e-3,Momentum=0.9,ConvergenceSteps=10,BatchSize=128,TestRepetitions=1,MaxEpochs=30,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,ADAM_beta1=0.9,ADAM_beta2=0.999,ADAM_eps=1.E-7,DropConfig=0.0+0.0+0.0+0.:Architecture=CPU"
: The following options are set:
: - By User:
: <none>
: - Default:
: Boost_num: "0" [Number of times the classifier will be boosted]
: Parsing option string:
: ... "!H:V:ErrorStrategy=CROSSENTROPY:VarTransform=G:WeightInitialization=XAVIER:InputLayout=1|1|7:BatchLayout=1|128|7:Layout=DENSE|64|TANH,DENSE|64|TANH,DENSE|64|TANH,DENSE|64|TANH,DENSE|1|LINEAR:TrainingStrategy=LearningRate=1e-3,Momentum=0.9,ConvergenceSteps=10,BatchSize=128,TestRepetitions=1,MaxEpochs=30,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,ADAM_beta1=0.9,ADAM_beta2=0.999,ADAM_eps=1.E-7,DropConfig=0.0+0.0+0.0+0.:Architecture=CPU"
: The following options are set:
: - By User:
: V: "True" [Verbose output (short form of "VerbosityLevel" below - overrides the latter one)]
: VarTransform: "G" [List of variable transformations performed before training, e.g., "D_Background,P_Signal,G,N_AllClasses" for: "Decorrelation, PCA-transformation, Gaussianisation, Normalisation, each for the given class of events ('AllClasses' denotes all events of all classes, if no class indication is given, 'All' is assumed)"]
: H: "False" [Print method-specific help message]
: InputLayout: "1|1|7" [The Layout of the input]
: BatchLayout: "1|128|7" [The Layout of the batch]
: Layout: "DENSE|64|TANH,DENSE|64|TANH,DENSE|64|TANH,DENSE|64|TANH,DENSE|1|LINEAR" [Layout of the network.]
: ErrorStrategy: "CROSSENTROPY" [Loss function: Mean squared error (regression) or cross entropy (binary classification).]
: WeightInitialization: "XAVIER" [Weight initialization strategy]
: Architecture: "CPU" [Which architecture to perform the training on.]
: TrainingStrategy: "LearningRate=1e-3,Momentum=0.9,ConvergenceSteps=10,BatchSize=128,TestRepetitions=1,MaxEpochs=30,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,ADAM_beta1=0.9,ADAM_beta2=0.999,ADAM_eps=1.E-7,DropConfig=0.0+0.0+0.0+0." [Defines the training strategies.]
: - Default:
: VerbosityLevel: "Default" [Verbosity level]
: CreateMVAPdfs: "False" [Create PDFs for classifier outputs (signal and background)]
: IgnoreNegWeightsInTraining: "False" [Events with negative weights are ignored in the training (but are included for testing and performance evaluation)]
: RandomSeed: "0" [Random seed used for weight initialization and batch shuffling]
: ValidationSize: "20%" [Part of the training data to use for validation. Specify as 0.2 or 20% to use a fifth of the data set as validation set. Specify as 100 to use exactly 100 events. (Default: 20%)]
DNN_CPU : [dataset] : Create Transformation "G" with events from all classes.
:
: Transformation, Variable selection :
: Input : variable 'm_jj' <---> Output : variable 'm_jj'
: Input : variable 'm_jjj' <---> Output : variable 'm_jjj'
: Input : variable 'm_lv' <---> Output : variable 'm_lv'
: Input : variable 'm_jlv' <---> Output : variable 'm_jlv'
: Input : variable 'm_bb' <---> Output : variable 'm_bb'
: Input : variable 'm_wbb' <---> Output : variable 'm_wbb'
: Input : variable 'm_wwbb' <---> Output : variable 'm_wwbb'
: Will now use the CPU architecture with BLAS and IMT support !
Factory : ␛[1mTrain all methods␛[0m
Factory : [dataset] : Create Transformation "I" with events from all classes.
:
: Transformation, Variable selection :
: Input : variable 'm_jj' <---> Output : variable 'm_jj'
: Input : variable 'm_jjj' <---> Output : variable 'm_jjj'
: Input : variable 'm_lv' <---> Output : variable 'm_lv'
: Input : variable 'm_jlv' <---> Output : variable 'm_jlv'
: Input : variable 'm_bb' <---> Output : variable 'm_bb'
: Input : variable 'm_wbb' <---> Output : variable 'm_wbb'
: Input : variable 'm_wwbb' <---> Output : variable 'm_wwbb'
TFHandler_Factory : Variable Mean RMS [ Min Max ]
: -----------------------------------------------------------
: m_jj: 1.0352 0.65399 [ 0.14661 13.098 ]
: m_jjj: 1.0218 0.36964 [ 0.34201 7.3920 ]
: m_lv: 1.0497 0.16065 [ 0.26679 3.6823 ]
: m_jlv: 1.0126 0.39935 [ 0.38441 6.5831 ]
: m_bb: 0.98070 0.53223 [ 0.093482 7.8598 ]
: m_wbb: 1.0338 0.35968 [ 0.38503 4.5425 ]
: m_wwbb: 0.96049 0.31009 [ 0.43228 4.0728 ]
: -----------------------------------------------------------
: Ranking input variables (method unspecific)...
IdTransformation : Ranking result (top variable is best ranked)
: -------------------------------
: Rank : Variable : Separation
: -------------------------------
: 1 : m_bb : 9.114e-02
: 2 : m_wwbb : 4.330e-02
: 3 : m_wbb : 4.241e-02
: 4 : m_jjj : 2.875e-02
: 5 : m_jlv : 1.905e-02
: 6 : m_jj : 3.432e-03
: 7 : m_lv : 2.855e-03
: -------------------------------
Factory : Train method: Likelihood for Classification
:
:
: ␛[1m================================================================␛[0m
: ␛[1mH e l p f o r M V A m e t h o d [ Likelihood ] :␛[0m
:
: ␛[1m--- Short description:␛[0m
:
: The maximum-likelihood classifier models the data with probability
: density functions (PDF) reproducing the signal and background
: distributions of the input variables. Correlations among the
: variables are ignored.
:
: ␛[1m--- Performance optimisation:␛[0m
:
: Required for good performance are decorrelated input variables
: (PCA transformation via the option "VarTransform=Decorrelate"
: may be tried). Irreducible non-linear correlations may be reduced
: by precombining strongly correlated input variables, or by simply
: removing one of the variables.
:
: ␛[1m--- Performance tuning via configuration options:␛[0m
:
: High fidelity PDF estimates are mandatory, i.e., sufficient training
: statistics is required to populate the tails of the distributions
: It would be a surprise if the default Spline or KDE kernel parameters
: provide a satisfying fit to the data. The user is advised to properly
: tune the events per bin and smooth options in the spline cases
: individually per variable. If the KDE kernel is used, the adaptive
: Gaussian kernel may lead to artefacts, so please always also try
: the non-adaptive one.
:
: All tuning parameters must be adjusted individually for each input
: variable!
:
: <Suppress this message by specifying "!H" in the booking option>
: ␛[1m================================================================␛[0m
:
: Filling reference histograms
: Building PDF out of reference histograms
: Elapsed time for training with 14000 events: 0.0812 sec
Likelihood : [dataset] : Evaluation of Likelihood on training sample (14000 events)
: Elapsed time for evaluation of 14000 events: 0.0111 sec
: Creating xml weight file: ␛[0;36mdataset/weights/TMVA_Higgs_Classification_Likelihood.weights.xml␛[0m
: Creating standalone class: ␛[0;36mdataset/weights/TMVA_Higgs_Classification_Likelihood.class.C␛[0m
: Higgs_ClassificationOutput.root:/dataset/Method_Likelihood/Likelihood
Factory : Training finished
:
Factory : Train method: Fisher for Classification
:
:
: ␛[1m================================================================␛[0m
: ␛[1mH e l p f o r M V A m e t h o d [ Fisher ] :␛[0m
:
: ␛[1m--- Short description:␛[0m
:
: Fisher discriminants select events by distinguishing the mean
: values of the signal and background distributions in a trans-
: formed variable space where linear correlations are removed.
:
: (More precisely: the "linear discriminator" determines
: an axis in the (correlated) hyperspace of the input
: variables such that, when projecting the output classes
: (signal and background) upon this axis, they are pushed
: as far as possible away from each other, while events
: of a same class are confined in a close vicinity. The
: linearity property of this classifier is reflected in the
: metric with which "far apart" and "close vicinity" are
: determined: the covariance matrix of the discriminating
: variable space.)
:
: ␛[1m--- Performance optimisation:␛[0m
:
: Optimal performance for Fisher discriminants is obtained for
: linearly correlated Gaussian-distributed variables. Any deviation
: from this ideal reduces the achievable separation power. In
: particular, no discrimination at all is achieved for a variable
: that has the same sample mean for signal and background, even if
: the shapes of the distributions are very different. Thus, Fisher
: discriminants often benefit from suitable transformations of the
: input variables. For example, if a variable x in [-1,1] has a
: a parabolic signal distributions, and a uniform background
: distributions, their mean value is zero in both cases, leading
: to no separation. The simple transformation x -> |x| renders this
: variable powerful for the use in a Fisher discriminant.
:
: ␛[1m--- Performance tuning via configuration options:␛[0m
:
: <None>
:
: <Suppress this message by specifying "!H" in the booking option>
: ␛[1m================================================================␛[0m
:
Fisher : Results for Fisher coefficients:
: -----------------------
: Variable: Coefficient:
: -----------------------
: m_jj: -0.051
: m_jjj: +0.187
: m_lv: +0.037
: m_jlv: +0.065
: m_bb: -0.207
: m_wbb: +0.532
: m_wwbb: -0.743
: (offset): +0.125
: -----------------------
: Elapsed time for training with 14000 events: 0.00624 sec
Fisher : [dataset] : Evaluation of Fisher on training sample (14000 events)
: Elapsed time for evaluation of 14000 events: 0.00127 sec
: <CreateMVAPdfs> Separation from histogram (PDF): 0.085 (0.000)
: Dataset[dataset] : Evaluation of Fisher on training sample
: Creating xml weight file: ␛[0;36mdataset/weights/TMVA_Higgs_Classification_Fisher.weights.xml␛[0m
: Creating standalone class: ␛[0;36mdataset/weights/TMVA_Higgs_Classification_Fisher.class.C␛[0m
Factory : Training finished
:
Factory : Train method: BDT for Classification
:
BDT : #events: (reweighted) sig: 7000 bkg: 7000
: #events: (unweighted) sig: 7000 bkg: 7000
: Training 200 Decision Trees ... patience please
: Elapsed time for training with 14000 events: 0.54 sec
BDT : [dataset] : Evaluation of BDT on training sample (14000 events)
: Elapsed time for evaluation of 14000 events: 0.0569 sec
: Creating xml weight file: ␛[0;36mdataset/weights/TMVA_Higgs_Classification_BDT.weights.xml␛[0m
: Creating standalone class: ␛[0;36mdataset/weights/TMVA_Higgs_Classification_BDT.class.C␛[0m
: Higgs_ClassificationOutput.root:/dataset/Method_BDT/BDT
Factory : Training finished
:
Factory : Train method: DNN_CPU for Classification
:
: Preparing the Gaussian transformation...
TFHandler_DNN_CPU : Variable Mean RMS [ Min Max ]
: -----------------------------------------------------------
: m_jj: 0.0042139 0.99787 [ -3.2801 5.7307 ]
: m_jjj: 0.0043508 0.99784 [ -3.2805 5.7307 ]
: m_lv: 0.0051611 1.0008 [ -3.2813 5.7307 ]
: m_jlv: 0.0044388 0.99830 [ -3.2803 5.7307 ]
: m_bb: 0.0041864 0.99765 [ -3.2793 5.7307 ]
: m_wbb: 0.0046426 0.99950 [ -3.2802 5.7307 ]
: m_wwbb: 0.0044594 0.99873 [ -3.2802 5.7307 ]
: -----------------------------------------------------------
: Start of deep neural network training on CPU using MT, nthreads = 1
:
TFHandler_DNN_CPU : Variable Mean RMS [ Min Max ]
: -----------------------------------------------------------
: m_jj: 0.0042139 0.99787 [ -3.2801 5.7307 ]
: m_jjj: 0.0043508 0.99784 [ -3.2805 5.7307 ]
: m_lv: 0.0051611 1.0008 [ -3.2813 5.7307 ]
: m_jlv: 0.0044388 0.99830 [ -3.2803 5.7307 ]
: m_bb: 0.0041864 0.99765 [ -3.2793 5.7307 ]
: m_wbb: 0.0046426 0.99950 [ -3.2802 5.7307 ]
: m_wwbb: 0.0044594 0.99873 [ -3.2802 5.7307 ]
: -----------------------------------------------------------
: ***** Deep Learning Network *****
DEEP NEURAL NETWORK: Depth = 5 Input = ( 1, 1, 7 ) Batch size = 128 Loss function = C
Layer 0 DENSE Layer: ( Input = 7 , Width = 64 ) Output = ( 1 , 128 , 64 ) Activation Function = Tanh
Layer 1 DENSE Layer: ( Input = 64 , Width = 64 ) Output = ( 1 , 128 , 64 ) Activation Function = Tanh
Layer 2 DENSE Layer: ( Input = 64 , Width = 64 ) Output = ( 1 , 128 , 64 ) Activation Function = Tanh
Layer 3 DENSE Layer: ( Input = 64 , Width = 64 ) Output = ( 1 , 128 , 64 ) Activation Function = Tanh
Layer 4 DENSE Layer: ( Input = 64 , Width = 1 ) Output = ( 1 , 128 , 1 ) Activation Function = Identity
: Using 11200 events for training and 2800 for testing
: Compute initial loss on the validation data
: Training phase 1 of 1: Optimizer ADAM (beta1=0.9,beta2=0.999,eps=1e-07) Learning rate = 0.001 regularization 0 minimum error = 0.724955
: --------------------------------------------------------------
: Epoch | Train Err. Val. Err. t(s)/epoch t(s)/Loss nEvents/s Conv. Steps
: --------------------------------------------------------------
: Start epoch iteration ...
: 1 Minimum Test error found - save the configuration
: 1 | 0.651984 0.621104 0.139335 0.0136105 88574.6 0
: 2 Minimum Test error found - save the configuration
: 2 | 0.600533 0.593788 0.138909 0.0138201 89024.7 0
: 3 Minimum Test error found - save the configuration
: 3 | 0.583313 0.585001 0.135985 0.0146345 91767 0
: 4 Minimum Test error found - save the configuration
: 4 | 0.573089 0.583266 0.136407 0.0136688 90729.8 0
: 5 Minimum Test error found - save the configuration
: 5 | 0.569853 0.577279 0.139145 0.0141369 89082.1 0
: 6 | 0.567075 0.577577 0.139534 0.0137917 88561.9 1
: 7 | 0.565542 0.577823 0.138833 0.013576 88905.5 2
: 8 | 0.561777 0.579471 0.138198 0.0136256 89393.6 3
: 9 | 0.559036 0.579106 0.138589 0.0138022 89239.9 4
: 10 Minimum Test error found - save the configuration
: 10 | 0.557756 0.577036 0.143422 0.0144908 86371.5 0
: 11 | 0.555033 0.579084 0.150611 0.0138679 81437.4 1
: 12 Minimum Test error found - save the configuration
: 12 | 0.555344 0.57561 0.144554 0.0137969 85165.6 0
: 13 | 0.552181 0.579708 0.140112 0.0137038 88095.3 1
: 14 | 0.550808 0.575698 0.140316 0.0143973 88438.2 2
: 15 | 0.549551 0.576135 0.141252 0.0140376 87537.1 3
: 16 Minimum Test error found - save the configuration
: 16 | 0.546296 0.575422 0.141264 0.0141817 87628.3 0
: 17 | 0.547657 0.580306 0.140435 0.0138716 87987.8 1
: 18 | 0.544742 0.579603 0.14095 0.014076 87771.9 2
: 19 | 0.545299 0.577286 0.140702 0.0139608 87864.4 3
: 20 | 0.542637 0.579561 0.139635 0.0140856 88698.5 4
: 21 | 0.540054 0.589641 0.139434 0.0140101 88787.2 5
: 22 | 0.539354 0.577679 0.140354 0.0139431 88093.7 6
: 23 | 0.53799 0.575765 0.142805 0.0142068 86595 7
: 24 | 0.535595 0.580316 0.14303 0.0139388 86264.5 8
: 25 | 0.531834 0.580043 0.144818 0.0139833 85115.2 9
: 26 | 0.532145 0.580602 0.140377 0.0138206 87992.6 10
: 27 | 0.530029 0.587493 0.139505 0.0139864 88720 11
:
: Elapsed time for training with 14000 events: 3.85 sec
: Evaluate deep neural network on CPU using batches with size = 128
:
DNN_CPU : [dataset] : Evaluation of DNN_CPU on training sample (14000 events)
: Elapsed time for evaluation of 14000 events: 0.0726 sec
: Creating xml weight file: ␛[0;36mdataset/weights/TMVA_Higgs_Classification_DNN_CPU.weights.xml␛[0m
: Creating standalone class: ␛[0;36mdataset/weights/TMVA_Higgs_Classification_DNN_CPU.class.C␛[0m
Factory : Training finished
:
: Ranking input variables (method specific)...
Likelihood : Ranking result (top variable is best ranked)
: -------------------------------------
: Rank : Variable : Delta Separation
: -------------------------------------
: 1 : m_bb : 5.483e-02
: 2 : m_wbb : 4.416e-02
: 3 : m_wwbb : 4.201e-02
: 4 : m_jjj : 4.949e-03
: 5 : m_lv : -2.642e-03
: 6 : m_jj : -5.516e-03
: 7 : m_jlv : -1.042e-02
: -------------------------------------
Fisher : Ranking result (top variable is best ranked)
: ---------------------------------
: Rank : Variable : Discr. power
: ---------------------------------
: 1 : m_bb : 1.180e-02
: 2 : m_wwbb : 7.816e-03
: 3 : m_wbb : 2.085e-03
: 4 : m_jlv : 5.619e-04
: 5 : m_jjj : 2.327e-04
: 6 : m_lv : 3.319e-05
: 7 : m_jj : 1.479e-05
: ---------------------------------
BDT : Ranking result (top variable is best ranked)
: ----------------------------------------
: Rank : Variable : Variable Importance
: ----------------------------------------
: 1 : m_bb : 2.045e-01
: 2 : m_wwbb : 1.687e-01
: 3 : m_jlv : 1.638e-01
: 4 : m_jjj : 1.413e-01
: 5 : m_wbb : 1.356e-01
: 6 : m_jj : 1.080e-01
: 7 : m_lv : 7.813e-02
: ----------------------------------------
: No variable ranking supplied by classifier: DNN_CPU
TH1.Print Name = TrainingHistory_DNN_CPU_trainingError, Entries= 0, Total sum= 15.0265
TH1.Print Name = TrainingHistory_DNN_CPU_valError, Entries= 0, Total sum= 15.7014
Factory : === Destroy and recreate all methods via weight files for testing ===
:
: Reading weight file: ␛[0;36mdataset/weights/TMVA_Higgs_Classification_Likelihood.weights.xml␛[0m
: Reading weight file: ␛[0;36mdataset/weights/TMVA_Higgs_Classification_Fisher.weights.xml␛[0m
: Reading weight file: ␛[0;36mdataset/weights/TMVA_Higgs_Classification_BDT.weights.xml␛[0m
: Reading weight file: ␛[0;36mdataset/weights/TMVA_Higgs_Classification_DNN_CPU.weights.xml␛[0m
Factory : ␛[1mTest all methods␛[0m
Factory : Test method: Likelihood for Classification performance
:
Likelihood : [dataset] : Evaluation of Likelihood on testing sample (6000 events)
: Elapsed time for evaluation of 6000 events: 0.00546 sec
Factory : Test method: Fisher for Classification performance
:
Fisher : [dataset] : Evaluation of Fisher on testing sample (6000 events)
: Elapsed time for evaluation of 6000 events: 0.000817 sec
: Dataset[dataset] : Evaluation of Fisher on testing sample
Factory : Test method: BDT for Classification performance
:
BDT : [dataset] : Evaluation of BDT on testing sample (6000 events)
: Elapsed time for evaluation of 6000 events: 0.0214 sec
Factory : Test method: DNN_CPU for Classification performance
:
: Evaluate deep neural network on CPU using batches with size = 1000
:
TFHandler_DNN_CPU : Variable Mean RMS [ Min Max ]
: -----------------------------------------------------------
: m_jj: 0.029995 0.98065 [ -3.1064 5.7307 ]
: m_jjj: 0.030151 0.98464 [ -2.9982 5.7307 ]
: m_lv: 0.011982 1.0066 [ -3.2274 5.7307 ]
: m_jlv: 0.0049774 1.0015 [ -3.0644 5.7307 ]
: m_bb: -0.036143 1.0111 [ -5.7307 5.7307 ]
: m_wbb: -0.0056377 1.0239 [ -3.0260 5.7307 ]
: m_wwbb: 0.0023364 1.0091 [ -3.1905 5.7307 ]
: -----------------------------------------------------------
DNN_CPU : [dataset] : Evaluation of DNN_CPU on testing sample (6000 events)
: Elapsed time for evaluation of 6000 events: 0.0306 sec
Factory : ␛[1mEvaluate all methods␛[0m
Factory : Evaluate classifier: Likelihood
:
Likelihood : [dataset] : Loop over test events and fill histograms with classifier response...
:
TFHandler_Likelihood : Variable Mean RMS [ Min Max ]
: -----------------------------------------------------------
: m_jj: 1.0368 0.66752 [ 0.16310 16.132 ]
: m_jjj: 1.0272 0.38070 [ 0.41899 8.9401 ]
: m_lv: 1.0522 0.17017 [ 0.29757 3.2605 ]
: m_jlv: 1.0135 0.40315 [ 0.41660 5.8195 ]
: m_bb: 0.96616 0.53867 [ 0.080986 8.2551 ]
: m_wbb: 1.0344 0.37776 [ 0.42068 6.4013 ]
: m_wwbb: 0.96122 0.31782 [ 0.44118 4.5350 ]
: -----------------------------------------------------------
Factory : Evaluate classifier: Fisher
:
Fisher : [dataset] : Loop over test events and fill histograms with classifier response...
:
: Also filling probability and rarity histograms (on request)...
TFHandler_Fisher : Variable Mean RMS [ Min Max ]
: -----------------------------------------------------------
: m_jj: 1.0368 0.66752 [ 0.16310 16.132 ]
: m_jjj: 1.0272 0.38070 [ 0.41899 8.9401 ]
: m_lv: 1.0522 0.17017 [ 0.29757 3.2605 ]
: m_jlv: 1.0135 0.40315 [ 0.41660 5.8195 ]
: m_bb: 0.96616 0.53867 [ 0.080986 8.2551 ]
: m_wbb: 1.0344 0.37776 [ 0.42068 6.4013 ]
: m_wwbb: 0.96122 0.31782 [ 0.44118 4.5350 ]
: -----------------------------------------------------------
Factory : Evaluate classifier: BDT
:
BDT : [dataset] : Loop over test events and fill histograms with classifier response...
:
TFHandler_BDT : Variable Mean RMS [ Min Max ]
: -----------------------------------------------------------
: m_jj: 1.0368 0.66752 [ 0.16310 16.132 ]
: m_jjj: 1.0272 0.38070 [ 0.41899 8.9401 ]
: m_lv: 1.0522 0.17017 [ 0.29757 3.2605 ]
: m_jlv: 1.0135 0.40315 [ 0.41660 5.8195 ]
: m_bb: 0.96616 0.53867 [ 0.080986 8.2551 ]
: m_wbb: 1.0344 0.37776 [ 0.42068 6.4013 ]
: m_wwbb: 0.96122 0.31782 [ 0.44118 4.5350 ]
: -----------------------------------------------------------
Factory : Evaluate classifier: DNN_CPU
:
DNN_CPU : [dataset] : Loop over test events and fill histograms with classifier response...
:
: Evaluate deep neural network on CPU using batches with size = 1000
:
TFHandler_DNN_CPU : Variable Mean RMS [ Min Max ]
: -----------------------------------------------------------
: m_jj: 0.0042139 0.99787 [ -3.2801 5.7307 ]
: m_jjj: 0.0043508 0.99784 [ -3.2805 5.7307 ]
: m_lv: 0.0051611 1.0008 [ -3.2813 5.7307 ]
: m_jlv: 0.0044388 0.99830 [ -3.2803 5.7307 ]
: m_bb: 0.0041864 0.99765 [ -3.2793 5.7307 ]
: m_wbb: 0.0046426 0.99950 [ -3.2802 5.7307 ]
: m_wwbb: 0.0044594 0.99873 [ -3.2802 5.7307 ]
: -----------------------------------------------------------
TFHandler_DNN_CPU : Variable Mean RMS [ Min Max ]
: -----------------------------------------------------------
: m_jj: 0.029995 0.98065 [ -3.1064 5.7307 ]
: m_jjj: 0.030151 0.98464 [ -2.9982 5.7307 ]
: m_lv: 0.011982 1.0066 [ -3.2274 5.7307 ]
: m_jlv: 0.0049774 1.0015 [ -3.0644 5.7307 ]
: m_bb: -0.036143 1.0111 [ -5.7307 5.7307 ]
: m_wbb: -0.0056377 1.0239 [ -3.0260 5.7307 ]
: m_wwbb: 0.0023364 1.0091 [ -3.1905 5.7307 ]
: -----------------------------------------------------------
:
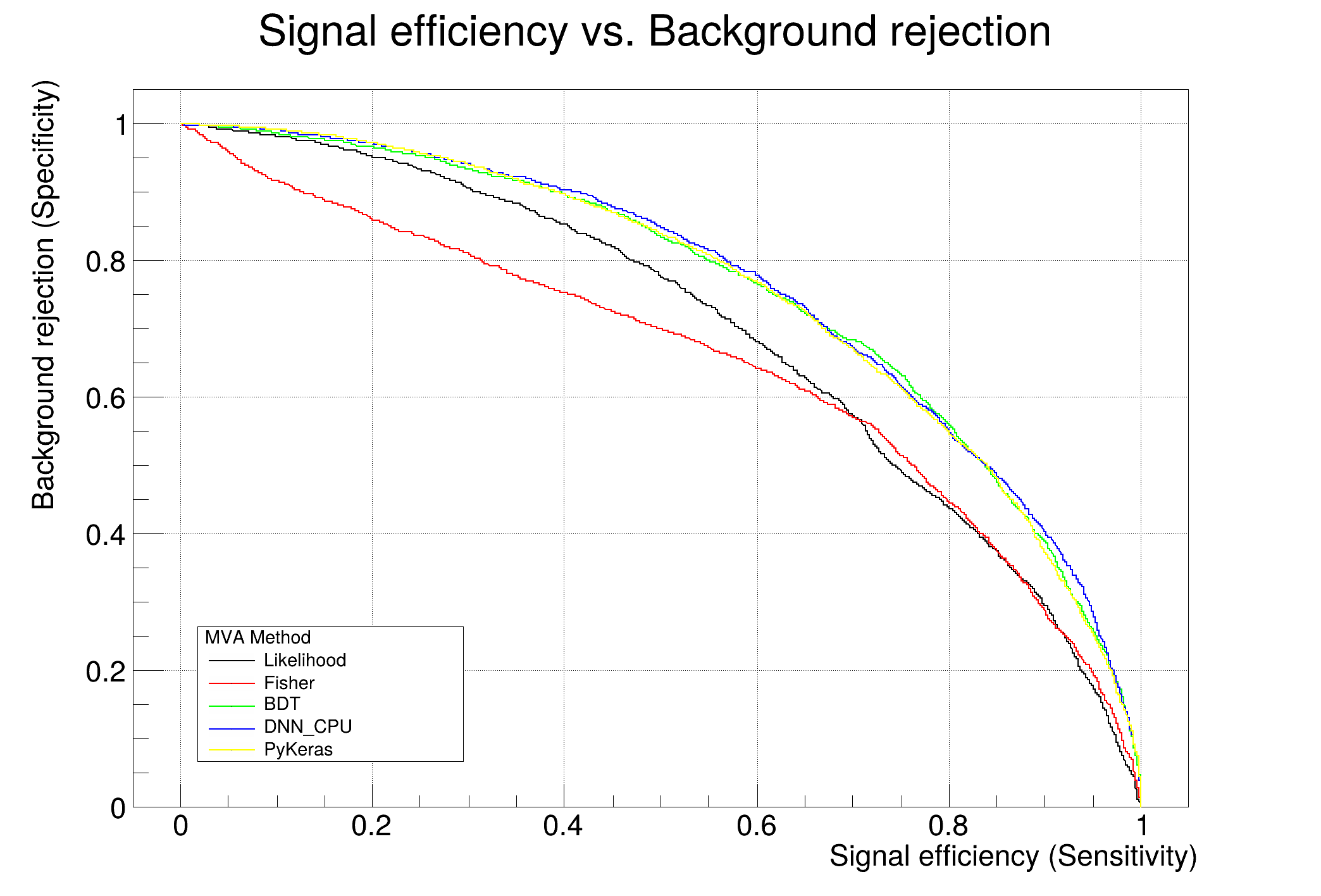
: Evaluation results ranked by best signal efficiency and purity (area)
: -------------------------------------------------------------------------------------------------------------------
: DataSet MVA
: Name: Method: ROC-integ
: dataset DNN_CPU : 0.769
: dataset BDT : 0.758
: dataset Likelihood : 0.699
: dataset Fisher : 0.654
: -------------------------------------------------------------------------------------------------------------------
:
: Testing efficiency compared to training efficiency (overtraining check)
: -------------------------------------------------------------------------------------------------------------------
: DataSet MVA Signal efficiency: from test sample (from training sample)
: Name: Method: @B=0.01 @B=0.10 @B=0.30
: -------------------------------------------------------------------------------------------------------------------
: dataset DNN_CPU : 0.125 (0.144) 0.408 (0.445) 0.688 (0.701)
: dataset BDT : 0.080 (0.095) 0.394 (0.394) 0.674 (0.685)
: dataset Likelihood : 0.058 (0.076) 0.309 (0.338) 0.584 (0.590)
: dataset Fisher : 0.017 (0.014) 0.128 (0.141) 0.500 (0.529)
: -------------------------------------------------------------------------------------------------------------------
:
Dataset:dataset : Created tree 'TestTree' with 6000 events
:
Dataset:dataset : Created tree 'TrainTree' with 14000 events
:
Factory : ␛[1mThank you for using TMVA!␛[0m
: ␛[1mFor citation information, please visit: http://tmva.sf.net/citeTMVA.html␛[0m